

이번 포스팅에서는 현재 kaggle에서 진행중인 classification competetion중 [SETI Breakthrough Listen - E.T. Signal Search] 데이터를 이전 포스팅에서 다룬 Swin transformer와 블로그에서 처음 소개하는 Weights and bias tool을 활용해서 학습해보려고 한다.
E.T. Signal Search?
이 데이터셋은 한마디로 정리하자면 시그널중에서 외계신호 즉 이상치를 탐지하는 것이다.
단지 시계열데이터가 아닌 이미지 데이터로 주어지고 그것이 비정상 즉 외계신호라면 1 아니라면 0을 예측해야하는 Binary Classification 문제이다.
Install accelerate & wandb
!pip install -q accelerate # multi gpu나 tpu에서 mixed precision을 쉽게 사용할 수 있게 해줌
!pip install wandb --upgrade- wandb는 weight and bias의 약어이다. 해당 모듈을 설치하면 wandb의 엄청난 기능을 사용할 수 있다.
Import Libraries
import warnings
import sklearn.exceptions
warnings.filterwarnings('ignore', category=DeprecationWarning)
warnings.filterwarnings('ignore', category=FutureWarning)
warnings.filterwarnings("ignore", category=sklearn.exceptions.UndefinedMetricWarning)
# Python
from tqdm import tqdm
from collections import defaultdict
import pandas as pd
import numpy as np
import os
import random
import glob
pd.set_option('display.max_columns', None)
# Visualization
from PIL import Image
import matplotlib.pyplot as plt
import seaborn as sns
import cv2
%matplotlib inline
sns.set(style='whitegrid')
# Image albumentations
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
# Utils
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.metrics import roc_auc_score
# Pytorch for Deep Learning
import torch
import torchvision
import timm
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, WeightedRandomSampler
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.cuda import amp
#GPU
from accelerate import Accelerator
accelerator = Accelerator()
# Weights and Biases Tool
import wandbDefine Configurations/Parameters
params = {
'seed': 42,
'model': 'swin_small_patch4_window7_224',
'size': 224,
'inp_chennels': 1,
'device': accelerator.device, # device(type='cuda')
'lr': 1e-4,
'weight_decay': 1e-6,
'batch_size': 32,
'num_workers': 0,
'epochs': 5,
'out_features': 1,
'name': 'CosineAnnealingLR',
'T_max': 10,
'min_lr': 1e-6,
'num_tta': 1
}- 사용할 모델은 swin transformer의 small 버전이다.
- 이 데이터셋은 RGB가 아닌 채널이 1이다.
- Binary classification이므로 out_features는 1
- Learning rate scheduler는 CosineAnnealingLR을 사용하였고 그 아래는 CosineAnnealingLR의 파라미터 값들이다.
Define Seed for Reproducibility
def seed_everything(seed=42):
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(params['seed'])
- deterministic한 결과를 얻기 위해 pytorch는 위와같이 seed값을 설정해준다.
Simple EDA
train_dir = ('../input/seti-breakthrough-listen/train')
test_dir = ('../input/seti-breakthrough-listen/test')
train_df = pd.read_csv('../input/seti-breakthrough-listen/train_labels.csv')
test_df = pd.read_csv('../input/seti-breakthrough-listen/sample_submission.csv')
def return_filepath(name, folder=train_dir):
path = os.path.join(folder, name[0], f'{name}.npy')
return path
train_df['image_path'] = train_df['id'].apply(lambda x: return_filepath(x))
test_df['image_path'] = test_df['id'].apply(lambda x: return_filepath(x, folder=test_dir))
train_df.head()output:
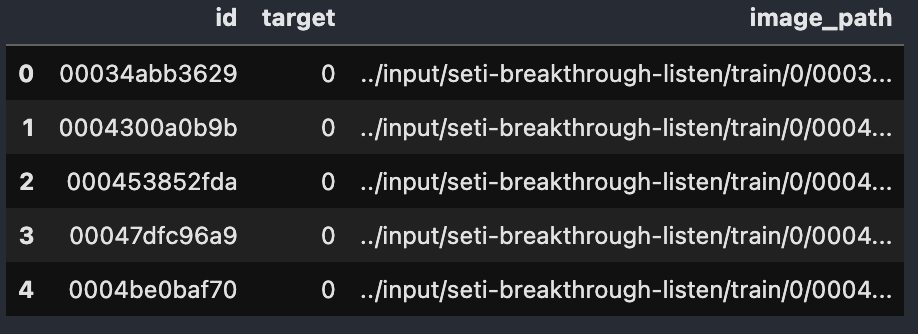
- 위 그림과 같이 이미지 경로 컬럼을 추가한다.
ax = plt.subplots(figsize=(12, 6))
sns.countplot(x='target', data=train_df);
plt.ylabel('Number of Observations',size=20);
plt.xlabel('Target', size=20);output:
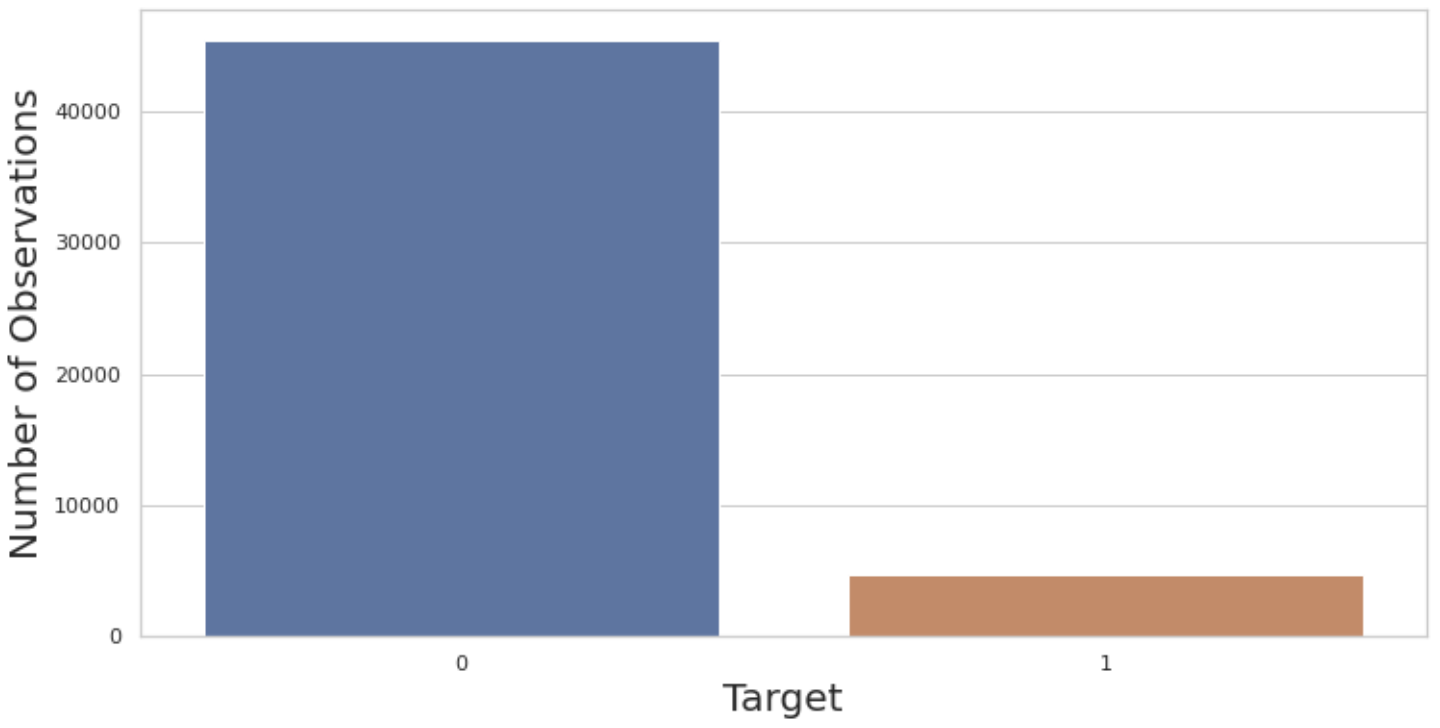
- 굉장히 Imbalance한 데이터셋임을 알 수 있다.
Image Augmentation
def get_train_transforms():
return A.Compose(
[
A.Resize(params['size'], params['size']),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Rotate(limit=180, p=0.5),
A.RandomBrightness(limit=0.6, p=0.5),
A.Cutout(
num_holes=10, max_h_size=12, max_w_size=12,
fill_value=0, always_apply=False, p=0.5),
A.ShiftScaleRotate(
shift_limit=0.25, scale_limit=0.1, rotate_limit=0),
ToTensorV2(p=1.0),
]
)
def get_valid_transforms():
return A.Compose(
[
A.Resize(params['size'],params['size']),
ToTensorV2(p=1.0)
]
)
def get_test_transforms():
return A.Compose(
[
A.Resize(params['size'],params['size']),
ToTensorV2(p=1.0)
]
)
- Augmentation은 albumentations을 통해 가장 많이 사용하는 기법들을 사용하였다.
Custom Dataset
class SETIDataset(Dataset):
def __init__(self, images_filepaths, targets, transform=None):
self.images_filepaths = images_filepaths
self.targets = targets
self.transform=transform
def __len__(self):
return len(self.images_filepaths)
def __getitem__(self, idx):
image_filepath = self.images_filepaths[idx]
image = np.load(image_filepath).astype(np.float32) # npz 파일 load
image = np.vstack(image).transpose((1, 0)) #ex (6, 273, 256) -> (1638, 256) -> (256, 1638)
if self.transform is not None:
image = self.transform(image=image)['image']
else:
image = image[np.newaxis, :, :]
image = torch.from_numpy(image).float()
label = torch.tensor(self.targets[idx]).float()
return image, label- 일반적인 Custom Dataset 구현 코드이다.
- 이미지는 .npz확장자로 numpy에서 load를 통해 바로 array로 만들 수 있다.
- 데이터가 처음에는 채널이 1이나 3이 아닌 6으로 되어있고 이를 가로로 긴 이미지로 변환한다. (2차원)
- 2차원 array를 transform이나 후처리과정에서 채널이 1인 3차원 데이터로 만들어 준다.
Train and Validation Data
(X_train, X_valid, y_train, y_valid) = train_test_split(train_df['image_path'], train_df['target'], test_size=0.2,
stratify=train_df['target'], shuffle=True, random_state=params['seed'])- train data를 train과 validation으로 나누어 준다.
- data가 imbalance하기 때문에 stratify 파라미터를 통해 라벨의 비율을 유지한채 분할한다.
train_dataset = SETIDataset(
images_filepaths=X_train.values,
targets=y_train.values,
transform=get_train_transforms()
)
valid_dataset = SETIDataset(
images_filepaths=X_valid.values,
targets=y_valid.values,
transform=get_valid_transforms()
)CutMix
def rand_bbox(W, H, lam):
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# 중심좌표
cx = np.random.randint(W)
cy = np.random.randint(H)
# corner 좌표
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
def cutmix(x, y, alpha=1.0):
if alpha > 0:
lam= np.random.beta(alpha, alpha) # 0~1
else:
lam=1
batch_size = x.size()[0]
index = torch.randperm(batch_size).to(params['device']) # 배치내의 다른 이미지와 mixup하기 위해
bbx1, bby1, bbx2, bby2 = rand_bbox(x.size()[2], x.size()[3], lam) # (32, 1, 224, 224)
x[:, bbx1:bbx2, bby1:bby2] = x[index, bbx1:bbx2, bby1:bby2] # 원래 이미지에 배치내의 다른 이미지를 삽입
y_a, y_b = y, y[index] # 이제 이미지당 정답은 2개
return x, y_a, y_b, lam
def cutmix_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)- 또다른 Augmentation으로 CutMix를 사용하였다. CutMix는 Naver Clover에서 제안한 augmentation 기법중 하나로 이미지 안에 어느 영역을 잘라서 다른 이미지의 일부로 대체하는 방법이다. (개의 사진에서 개의 머리만 고양이로 바뀌는 것 등등..)
- 이때 대체할 다른 이미지는 현재 배치사이즈 안에있는 다른 이미지로부터 가져온다.
- 각 함수에 대해 짧게 정리하자면 아래와 같다.
- rand_bbox : 현재 배치만큼의 이미지들에서 잘라내고 대체할 박스좌표를 구하는 함수
- cutmix : cutmix 기법을 활용한 이미지들과 새로운 라벨 및 사용된 비율(lambda)값을 반환하는 함수
- cutmix_criterion : 2개의 정답에 대해 각각의 loss값을 구하여 최종 loss를 반환하는 함수
Custom Class for Monitoring Loss and ROC
class MetricMonitor:
def __init__(self, float_precision=3):
self.float_precision = float_precision
self.reset()
def reset(self):
self.metrics = defaultdict(lambda: {"val": 0, "count": 0, "avg": 0})
def update(self, metric_name, val):
metric = self.metrics[metric_name]
metric["val"] += val
metric["count"] += 1
metric["avg"] = metric["val"] / metric["count"]
def __str__(self):
return " | ".join(
[
"{metric_name}: {avg:.{float_precision}f}".format(
metric_name=metric_name, avg=metric["avg"],
float_precision=self.float_precision
)
for (metric_name, metric) in self.metrics.items()
]
)- loss값이나 accuracy를 모니터링 하기위해 구현된 함수 (특히 캐글에서 이 class를 많이 구현하는 것 같다.)
def use_roc_score(output, target):
try:
y_pred = torch.sigmoid(output).cpu()
y_pred = y_pred.detach().numpy()
target = target.cpu()
return roc_auc_score(target, y_pred)
except:
return 0.5- 해당 대회는 accuracy를 ROC Curve를 통해 측정한다.
- 모델의 output을 sigmoid를 취해주고 sklearn라이브러리를 통해 score를 구한다.
Weighted Random Sampler
class_counts = y_train.value_counts().to_list() # [36377, 3755]
num_samples = sum(class_counts) # 40132
labels = y_train.to_list()
class_weights = [num_samples/class_counts[i] for i in range(len(class_counts))]
weights = [class_weights[labels[i]] for i in range(int(num_samples))]
sampler = WeightedRandomSampler(torch.DoubleTensor(weights), int(num_samples))- Weighted Random Sampler는 Imbalance 데이터에 대한 성능을 높일 수 있는 방법중 하나로서 dataloader에서 데이터가 뽑힐때 모든 클래스가 같은 비율로 나오도록 하게 하는 방식이다.
- 데이터가 없는데 어떻게 같은 비율로 데이터가 나올까? -> 그냥 같은 데이터를 재활용한다..
- 이 방법에 대해 개인적으로 한가지 의문점이 있는데 같은 데이터를 많이 사용하면 overfitting이 일어나지 않을까? 라는 생각이 든다. 이 부분에 대해서는 더 파헤쳐 봐야겠다.
- WeightedRandomSampler의 작동방식은 간단하다. 각각의 클래스들의 전체 데이터수에 대한 weights를 구하기만 하면 된다.
train_loader = DataLoader(
train_dataset, batch_size=params['batch_size'], sampler = sampler, # sampler로 균형맞춤
num_workers=params['num_workers'], pin_memory=True)
val_loader = DataLoader(
valid_dataset, batch_size=params['batch_size'], shuffle=False,
num_workers=params['num_workers'], pin_memory=True)- 위에서 구한 sampler를 dataloader에서 사용할 수 있다.
- sampler는 train과정에서만 사용한다.
Swin Transformer
- Swin Transformer에 대한 모델구현은 이전포스팅에서 다루었기 때문에 timm에서 pretrained model을 가져와서 fine tuning을 해보았다.
- 먼저 timm에 저장되어있는 swin transformer 관련 모델은 아래와 같다.
# timm에 있는 swin model 종류
timm.list_models('swin*')output:
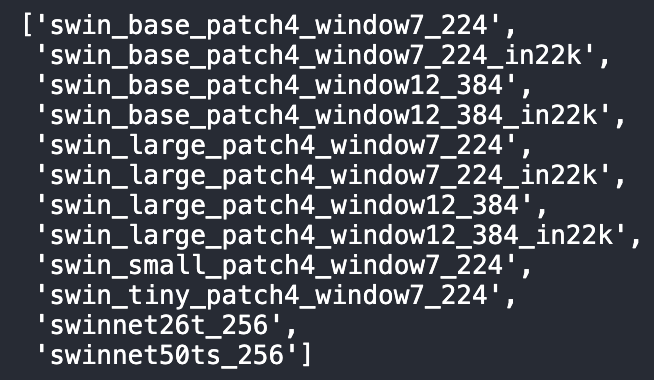
class SwinNet(nn.Module):
def __init__(self, model_name=params['model'], out_features=params['out_features'],
inp_channels=params['inp_chennels'], pretrained=True):
super().__init__()
self.model = timm.create_model(model_name, pretrained=pretrained,
in_chans=inp_channels)
n_features = self.model.head.in_features
self.model.head = nn.Linear(n_features, out_features, bias=True)
def forward(self, x):
return self.model(x)- fine tuning을 하기 위해 간단한 class를 구현해야 한다.
- 사용할 모델을 정의하고 input_channel과 output_channel를 바꿔준다.
Define Loss Function, Optimizer and Scheduler
model = SwinNet()
model = model.to(params['device'])
criterion = nn.BCEWithLogitsLoss().to(params['device'])
optimizer = torch.optim.Adam(model.parameters(), lr=params['lr'],
weight_decay=params['weight_decay'],
amsgrad=False)
scheduler = CosineAnnealingLR(optimizer, T_max=params['T_max'],
eta_min=params['min_lr'],
last_epoch=-1)Mixed Precision Training
- Mixed Precision Training에대해 간단히 소개하면 floating point를 32bit가 아닌 16bit를 사용함으로써 연산량 감소와 배치사이즈 증가에 대한 장점을 가지고 있으며 forward와 backward 계산에서는 16bit를 사용하고 오차 누적에 대한 문제가 있어 weight update시에만 32bit로 다시 전환하는 방식을 취한다.
- Auto mixed precision 모듈만 알고있었는데 accelerator에 대해 처음 알게 되었다.
def train(train_loader, model, criterion, optimizer, epoch, params):
metric_monitor = MetricMonitor()
model.train()
stream = tqdm(train_loader)
scaler = amp.GradScaler()
for i , (images, target) in enumerate(stream, start=1):
images = images.to(params['device'])
target = target.to(params['device']).float().view(-1, 1) # (32x1)
images, targets_a, targets_b, lam = cutmix(images, target.view(-1, 1))
with amp.autocast(enabled=True):
output = model(images)
loss = cutmix_criterion(criterion, output, targets_a, targets_b, lam)
accelerator.backward(scaler.scale(loss))
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
roc_score = use_roc_score(output, target)
metric_monitor.update('Loss', loss.item())
metric_monitor.update('ROC', roc_score)
wandb.log({"Train Epoch":epoch,"Train loss": loss.item(), "Train ROC":roc_score})
stream.set_description( # tqdm
"Epoch: {epoch}. Train. {metric_monitor}".format(
epoch=epoch,
metric_monitor=metric_monitor)
)- 로직을 빠르게 훑어 보면
- 먼저 albumentation을 거쳐온 이미지들을 cutmix를 적용하고 모델로 보낸다.
- Mixed precision 방식으로 학습이 되고 위에서 구현한 모니터링 클래스를 통해 console에서 학습 진행상황을 파악한다.
- 여기서 wandb.log라는 부분은 weights and bias의 프로젝트 안에 logging 하는 것이다. (아래에서 자세히)
def validate(val_loader, model, criterion, epoch, params):
metric_monitor = MetricMonitor()
model.eval()
stream = tqdm(val_loader)
final_targets = []
final_outputs = []
with torch.no_grad():
for i, (images, target) in enumerate(stream, start=1):
images = images.to(params['device'], non_blocking=True)
target = target.to(params['device'], non_blocking=True).float().view(-1, 1)
output = model(images)
loss = criterion(output, target)
roc_score = use_roc_score(output, target)
metric_monitor.update('Loss', loss.item())
metric_monitor.update('ROC', roc_score)
wandb.log({"Valid Epoch": epoch, "Valid loss": loss.item(), "Valid ROC":roc_score})
stream.set_description(
"Epoch: {epoch}. Validation. {metric_monitor}".format(
epoch=epoch,
metric_monitor=metric_monitor)
)
targets = target.detach().cpu().numpy().tolist()
outputs = output.detach().cpu().numpy().tolist()
final_targets.extend(targets)
final_outputs.extend(outputs)
return final_outputs, final_targetsRunning Train and Evaluation and Monitoring on Weights and Biases
best_roc = -np.inf
best_epoch = -np.inf
best_model_name = None
for epoch in range(1, params['epochs']+1):
run = wandb.init(project='Seti-Swin',
config=params,
job_type='train',
name=f'Swin Transformer_epoch{epoch}')
train(train_loader, model, criterion, optimizer, epoch, params)
predictions, valid_targets = validate(val_loader, model, criterion, epoch, params)
roc_auc = round(roc_auc_score(valid_targets, predictions), 3)
torch.save(model.state_dict(),f"{params['model']}_{epoch}_epoch_{roc_auc}_roc_auc.pth")
if roc_auc > best_roc:
best_roc = roc_auc
best_epoch = epoch
best_model_name = f"{params['model']}_{epoch}_epoch_{roc_auc}_roc_auc.pth"
scheduler.step()- wandb.init을 통해 프로젝트를 생성하고 학습을 하면서 실시간으로 학습정보를 담게 된다.
output:
- 동영상을 보면 알 수 있듯이 에폭별로 ROC score와 Loss에 대한 log를 시각화해 주는것을 알 수 있다.
print(f'The best ROC: {best_roc} was achieved on epoch: {best_epoch}.')
print(f'The Best saved model is: {best_model_name}')output:

Test Time Augmentation
model = SwinNet()
model.load_state_dict(torch.load(best_model_name))
model = model.to(params['device'])
model.eval()
predicted_labels = None
for i in range(params['num_tta']):
test_dataset = SETIDataset(
images_filepaths = test_df['image_path'].values,
targets = test_df['target'].values,
transform = get_test_transforms()
)
test_loader = DataLoader(
test_dataset, batch_size=params['batch_size'],
shuffle=False, num_workers=params['num_workers'],
pin_memory=True
)
temp_preds = None
with torch.no_grad():
for (images, target) in tqdm(test_loader):
images = images.to(params['device'], non_blocking=True)
output = model(images)
predictions = torch.sigmoid(output).cpu().numpy()
if temp_preds is None:
temp_preds = predictions
else:
temp_preds = np.vstack((temp_preds, predictions)) #예측값을 array에 담음
if predicted_labels is None:
predicted_labels = temp_preds
else:
predicted_labels += temp_preds # tta가 여러번이면 값을 계속 더해줌
predicted_labels /= params['num_tta'] # tta 횟수만큼 나누어서 평균을 냄 (최종 model 결과값)- TTA는 Test단계에서 augmentation을 통해 모델의 output을 여러개 남겨 그것들을 평균내어 성능을 높이는 일종의 Ensemble기법이다.
- 현재 코드에서는 TTA를 적용하지 않았다. ( params['num_tta'] = 1 )
Submission File
sub_df = pd.DataFrame()
sub_df['id'] = test_df['id']
sub_df['target'] = predicted_labels
sub_df.to_csv('submission.csv', index=False)
sub_df.head()output:
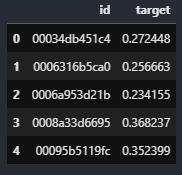
- 이 대회는 test dataset에 대한 모델의 output의 확률값을 그대로 제출해야한다.
ENDING
이번 포스팅에서는 accelerator, timm, w&b, cutmix등 여러가지 시도를 해보았다. 특히 weights and bias는 기존의 Tensorboard에 비해 훨씬 다양한 기능과 깔끔한 UI를 제공한다. 이 tool은 특히 hyperparameter optimization을 도와주는 Sweep, 그리고 데이터와 모델을 저장하고 버전을 관리할 수 있는 Artifacts라는 기능을 제공한다.
다음에 Weights and Biases에 대해 자세히 다뤄볼 예정이다. keep going~!
Reference
Timm - https://github.com/rwightman/pytorch-image-models
W&B - https://wandb.ai/site
'Project' 카테고리의 다른 글
| [Part.3] Image Classification on MLOps (4) | 2022.03.02 |
|---|---|
| [Part.2] Image Classification on MLOps (0) | 2022.02.28 |
| [Part.1] Image Classification on MLOps (2) | 2022.02.28 |
| 비전 프로젝트 : CVFM(Computer Vision For Market) (0) | 2021.05.01 |
