마이크로서비스 패턴
클라우드의 등장 이후 서비스를 구성하는 기능을 작은 독립된 서비스로 분할하는 MSA(Micro Service Architecture)가 확산되고 있다. MSA는 서비스 간 결합도를 낮춰 독립성을 높임과 동시에, 각 서비스를 최적의 라이브러리나 프로그래밍 언어로 개발할 수 있게 한다.
이번 포스팅에서는 MSA 방법론을 머신러닝의 추론기에 적용한 마이크로서비스 패턴에 대해 알아보자. (직렬 마이크로서비스 패턴은 이전 포스팅인 전처리 추론 패턴과 구현방식이 매우 비슷하기 때문에 짧게 넘어가고 병렬 마이크로서비스 패턴으로 넘어간다.)
직렬 마이크로서비스 패턴
1. Use Case
- 여러 개의 추론기로 구성되는 시스템에서 추론기 사이의 의존성이 명확한 경우.
- 여러 개의 추론기로 구성되는 시스템에서 추론의 실행 순서가 정해져 있는 경우.
2. 해결하려는 과제
하나의 입력 데이터에 대해 여러 개의 추론기를 조합하여 하나의 추론을 완성하는 workflow가 있다. 어떠한 모델의 추론 결과가 다른 모델의 입력 데이터가 되는 경우를 생각해보자. ( ex.고양이가 찍힌 사진에서 고양이의 위치와 품종을 분류하고 삼색 고양이라면 일본식으로, 서양품종 고양이라면 서양식으로 스타일을 변환하는 서비스)
사진 내의 고양이에 대해 Object Detection 모델로 객체를 탐지하고 그 결과를 스타일 변환 모델의 입력으로 넣어 서로 다른 두 개의 추론을 차례로 실행하는 흐름이 될 것이다.
이처럼 여러 추론 모델들이 의존관계를 가지고 차례대로 수행되는 용도는 많이 찾아볼 수 있다. 이때 모든 추론 모델을 하나의 추론기에 포함시킨다면 추론기의 사이즈가 방대해지고 효율성이 떨어진다. 추론 모델과 추론기를 1대1로 구성하는 것이 개발과 운용 측면에서 유연하다.
3. Architecture
직렬 마이크로서비스 패턴에서는 의존관계가 있는 여러 개의 추론 모델을 각각의 추론기로 배치하여 추론을 하나로 이어 붙인 workflow를 실현한다.
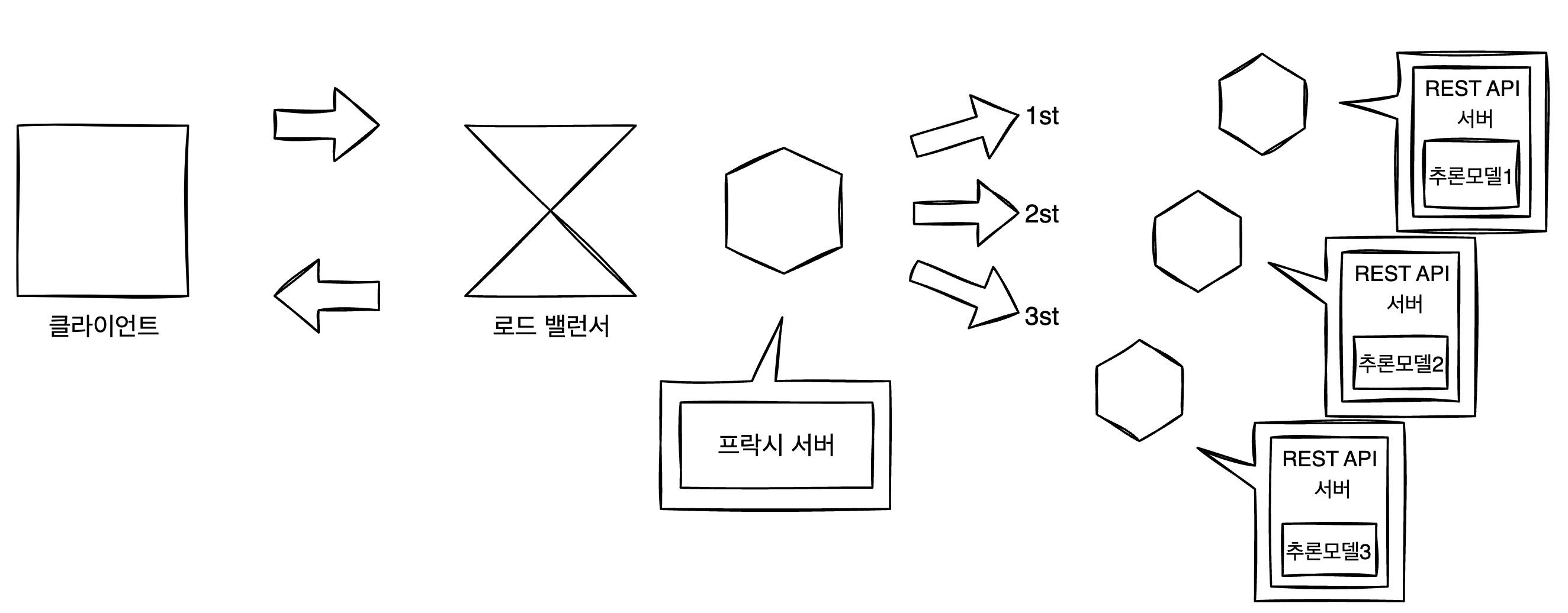
각 추론기는 MSA로 배치하고, 클라이언트와 추론기 사이에는 프락시를 배치한다. 클라이언트로부터의 요청은 프락시가 중개하며 각 추론기로 요청을 보낸다. 추론기는 프락시로부터 요청을 받는 MSA로 배치되기 때문에 각 추론기의 갱신은 다른 추론기에 영향을 주지 않고 유연하게 실행할 수 있다. 단, 전처리 · 추론 패턴과 마찬가지로, 추론 모델이 다른 추론 모델에 의존해서 학습된 경우 추론 모델 한쪽만 갱신하는 것은 불가능하며, 일괄적으로 추론기를 갱신해야 한다.
또한 프락시는 클라이언트와 추론기 전체를 중개하기 때문에 프락시에서 모든 요청을 제어할 수 있어 요청 처리 경로를 유연하게 바꿀 수 있다. 예를 들어 고양이 이미지에서 Object Detection 모델에 문제가 있는 경우, 객체 인식을 건너뛰고 Image Classification을 진행하는 흐름도 가능하다. 물론 결과는 이전과 다르겠지만, 요청에 응답하지 않고 에러를 발생시키는 것 보다 최소한의 응답이라도 가능하게 해주는 것이 서비스로서 유익한 상황에서는 유효하다. 특정 추론기에서 에러가 발생해도 전체를 멈추지 않는 구성인 것이다. 시스템의 요건에 따라 달라지겠지만, 프락시를 두는것은 운용과 가동을 유연하게 하기 위함이다.
4. 구현
직렬 MSA 패턴은 전처리 · 추론 패턴과 거의 동일하기 때문에 구현은 생략한다.
5. 이점
- 각 추론 모델을 순서대로 실행하는 것이 가능하다.
- 앞의 추론모델의 결과에 따라 다음 모델로의 추론 요청을 선택하는 구성도 가능하다.
- 각 추론에서 서버나 코드베이스를 분할해 효율적인 리소스의 활용과 장애 분리가 가능하다.
6. 검토사항
직렬 MSA 패턴처럼 여러개의 추론기를 배포한 상황에서는 각 추론기의 소요 시간의 합이 곧 클라이언트에 대한 응답 소요 시간이다. 따라서 각 추론기의 추론이 빨라도 서비스 전체로 보면 응답이 늦는 경우가 있다. 이때는 가벼운 모델을 사용하거나 최적화 또는 리소스 증강을 하는 등 전체적인 지연의 개선이 필요하다.
하나의 추론기에 모든 모델을 도입하여 연계시키는 구성에 비하면 직렬 MSA 패턴은 아무래도 응답이 늦어지기 마련이다. 모든 모델을 포함한 추론기는 서버 내부에서 통신이 완결되기 때문에 모델 간 데이터 통신의 지연을 최소화 할 수 있다. 하지만 이러한 경우에는 개별 모델의 갱신이나 스케일 아웃은 어렵다는 단점이 있다.
한편 직렬 MSA 패턴은 추론기별 스케일 아웃이나 모델의 갱신이 유연한 대신, 서버 간 지연이 발생한다. 운용상으로는 직렬 MSA 패턴이 더 유연하지만, 속도가 우선이라면 모든 모델을 포함한 하나의 추론기를 사용하는 것도 나쁘지 않은 선택이 될 수 있다.
병렬 마이크로서비스 패턴
여러 개의 추론기를 결합하는 방법에는 병렬 처리로 하는 방법도 있다. 병렬 MSA 패턴에서는 추론기를 병렬로 구성해 각 추론기에 개별적으로 요청을 보낸다. 즉 병렬 MSA 패턴은 서로 다른 모델의 추론 결과를 집약시키는 구조라고 이해할 수 있다.
1. Use Case
- 의존관계가 없는 여러 개의 추론을 병렬로 실행할 경우
- 여러 개의 추론 결과를 마지막으로 집계하는 workflow일 경우
- 하나의 데이터에 대해 여러 개의 추론 결과를 필요로 할 경우
2. 해결하려는 과제
하나의 데이터를 반드시 하나의 추론기로 추론해야 한다는 규칙은 없다. 하나의 데이터에 대해 분류와 회귀로 서로 다른 추론 결과를 얻어 놓고, 각 결과를 다른 목적으로 사용하고 싶은 경우도 드물지 않다. 예를 들어 웹 서비스의 이벤트 로그라면 동일한 로그에 대해 분류나 회귀, 즉 위반 행동 검지를 분류 문제로, 구매 예측을 회귀 문제로 접근하는 방법을 생각해볼 수 있다.
또 하나는 이진 분류를 여러번 실행한 결과를 집계해서 하나의 통합된 추론 결과로 만들기도 한다. 웹 서비스의 이벤트 로그에 대해 서로 다른 몇 가지의 위반 행동을 검지하고 싶은 경우에도 개별적인 위반 행동에 대한 검지 모델을 이진 분류로 개발해 병렬로 추론하는 방법도 있다.
이처럼 동일한 데이터에 대해 여러 추론기를 수평으로 배치해 MSA로 실행하는 아키텍처가 병렬 MSA 패턴이다.
3. Architecture
병렬 MSA 패턴에서는 의존관계가 없는 여러 개의 추론 모델을 병행하여 실행하고, 각 추론기로 동시에 추론 요청을 전송하여 서로 다른 여러 개의 추론 결과를 얻는다. 직렬 MSA와 마찬가지로 클라이언트와 추론기 사이에 중개 역할을 하는 독립적인 프락시를 두어 실현한다. 프락시를 배치하여 데이터의 취득이나 추론 결과를 집약하는 등 각종 Task를 클라이언트로부터 격리시킬 수 있다.
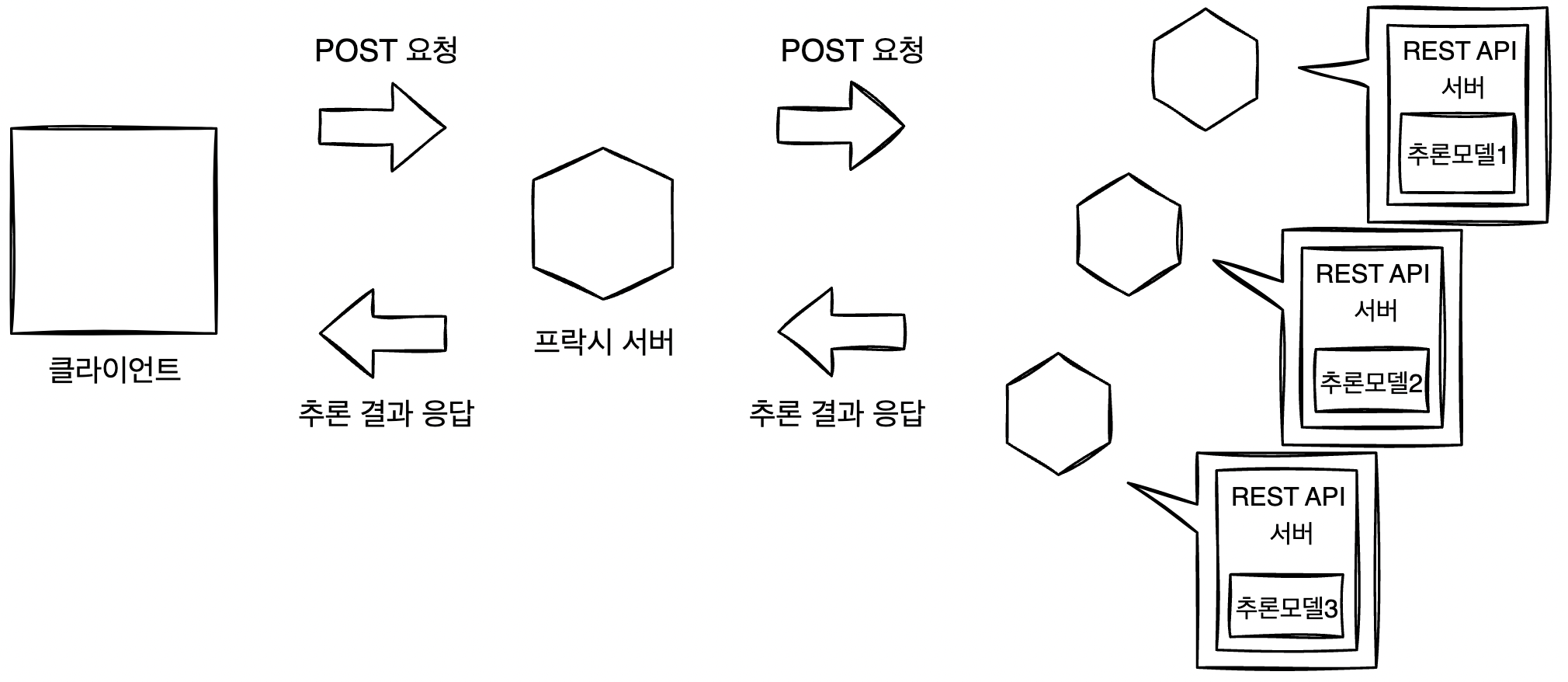
프락시를 두면 머신러닝의 추론 결과에 따라 클라이언트의 응답을 제어할 수 있다는 장점이 있다. 위반 행동 검지를 예로 들자면, 위한 행동의 리스크는 다양하다. 중대한 범죄 행위와 같은 위반도 있는가 하면, 비매너 정도로 끝나는 위반도 있을 것이다. 웹 서비스 이용자 수가 늘어나면 이러한 모든 위반에 대해 대응하는 것에는 한계가 있다. 리스크가 낮은 위반은 일단 뒤로 미뤄두고, 중요하다고 생각하는 위한 행동을 실시간으로 집계해 경보를 울리는 workflow가 필요해진다. 그렇다면 머신러닝의 위반 검지로 얻은 추론 결과에 따른 로직이 필요하다. 이때 프락시에 해당 로직을 구현하고 추론 결과에 대한 응답을 제어함으로써 workflow를 유연하게 관리할 수 있다.
추론을 위한 입력 데이터는 프락시에서 일괄 수집할 수도 있지만, 각 추론 서버에서 직접 취득하는 방법도 있다. 전자(위 그림)는 DWH나 Storage 액세스 횟수를 줄여 오버헤드를 삭감할 수 있다는 것이 장점이고, 후자(아래 그림)는 각 모델이 필요한 데이터를 취득해 조금 더 복잡한 workflow를 실현할 수 있다는 장점이 있다.
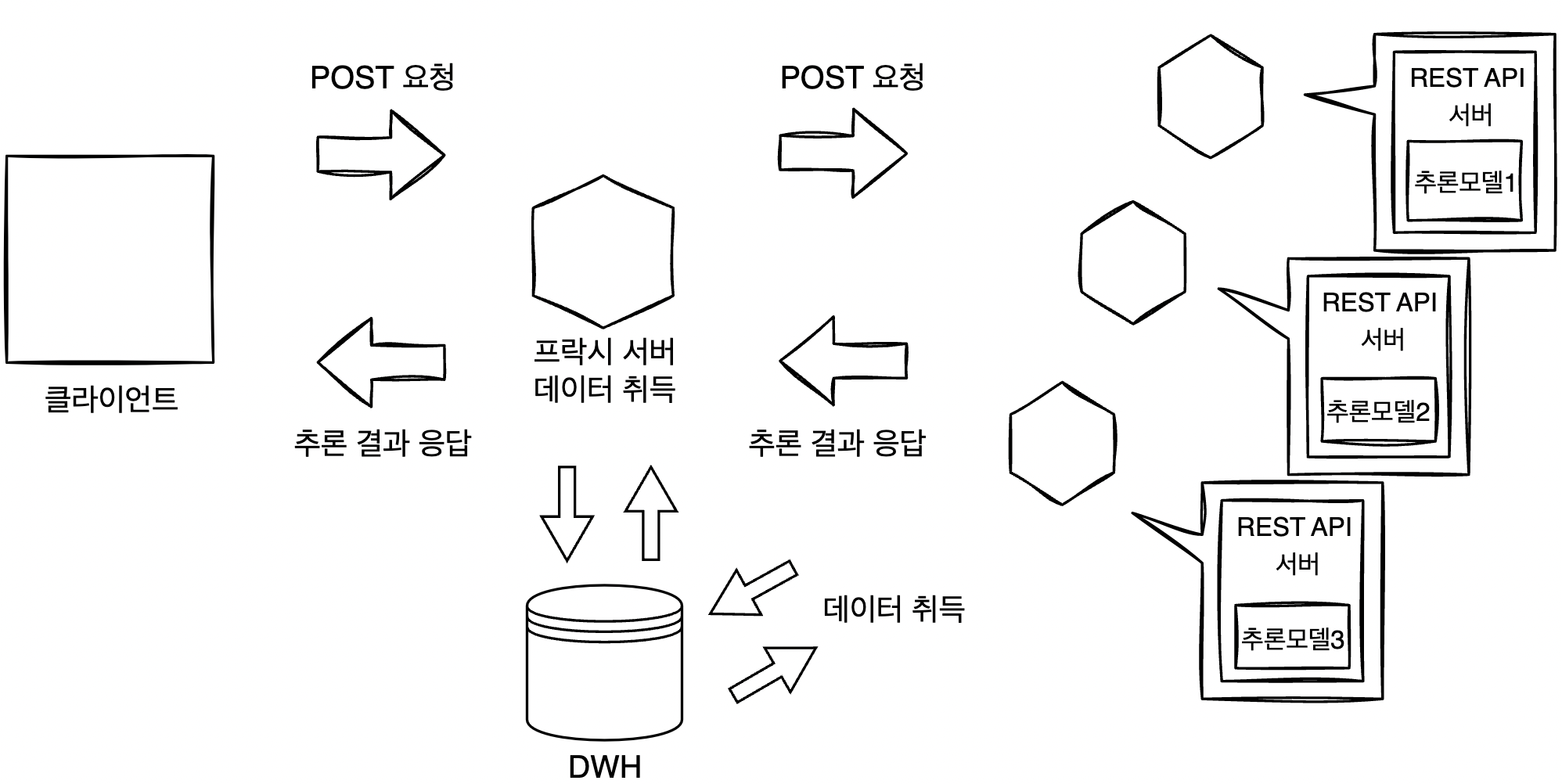
추론은 용도에 따라 동기적 또는 비동기적으로 실행하는 방침을 정해야 한다. 동기적으로 실행하는 경우로는 모든 추론을 취득한 후 결과를 집계하는 것을 생각할 수 있다. 이 케이스에서는 모든 추론 결과를 얻을 때까지 후속 workflow가 진행되지 않는다. 비동기적으로 실행하는 경우는 추론을 얻는 즉시 액션을 취하는 경우다.
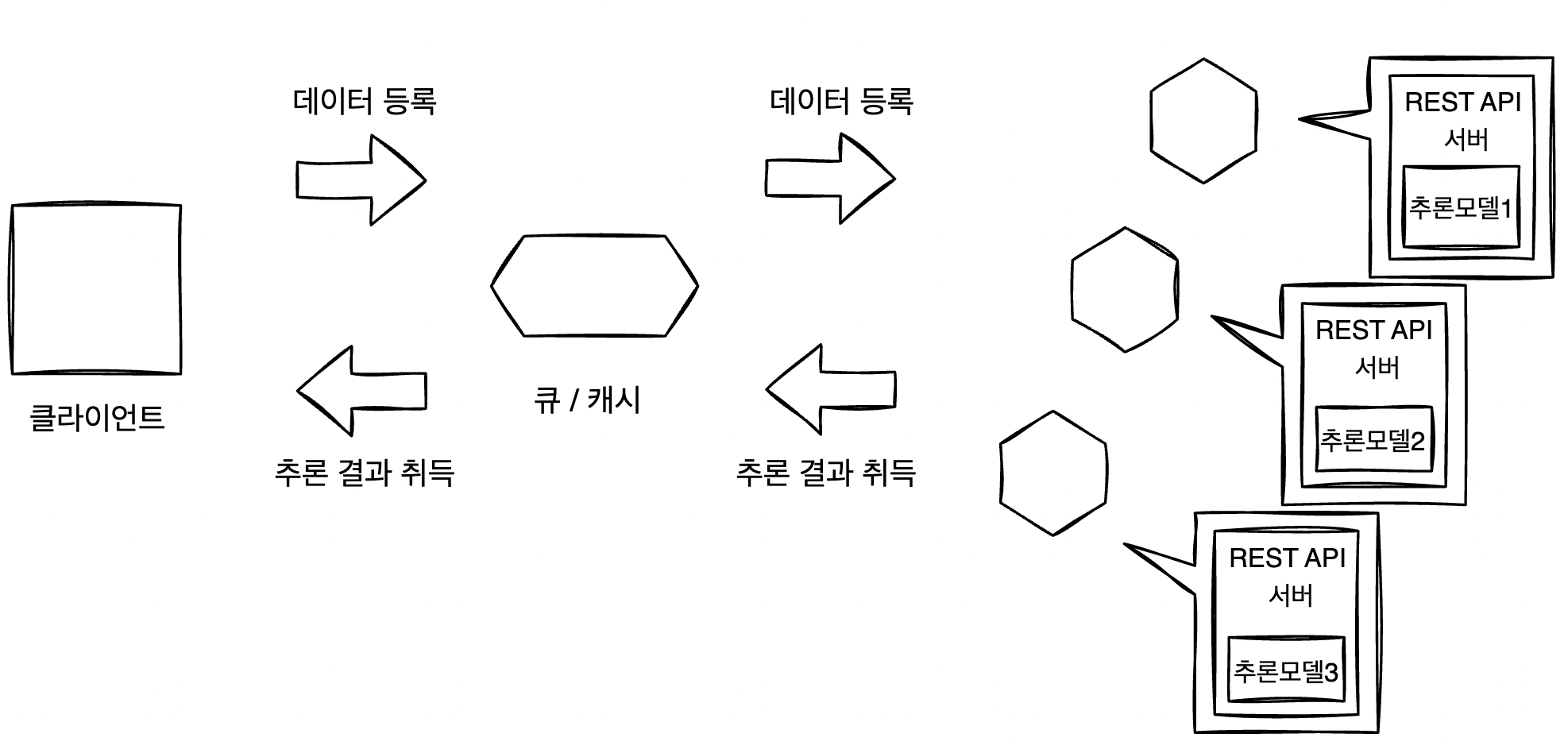
이때는 다른 추론 결과를 기다리지 않고 결과가 나온 순서대로 처리해야 한다. 동일 화면에서 여러 개의 콘텐츠가 게재되어 있는 웹 어플리케이션이라면 비동기 추론의 use case가 유용하다.
지금 다루는 패턴은 MSA 아키텍쳐이기 때문에 추론기의 추가와 삭제를 유연하게 제어할 수만 있다면 운용이 매우 쉬워진다. 추론기의 추가와 삭제는 프락시로 컨트롤하는 것이 좋다. 각각의 추론기를 REST API나 gRPC 등에서 개별 엔드포인트를 갖는 서비스로 가동시켜 각 엔드포인트에 대한 요청을 프락시 환경변수를 통해 추가, 삭제할 수 있게 한다. 이렇게 하면 신속하게 릴리스해야 할 추론기를 추가하거나 추론 성능이 나쁜 추론기를 제외하는 것이 쉬워진다.
4. 구현
병렬 마이크로 패턴에서는 Iris 데이터셋의 클래스별로 binary classification 모델 3개를 간단하게 만들어 서로 다른 추론기로 가동시킨다. 추론기로의 요청을 프락시가 중개하며 프락시를 경유해서 전 추론기에 추론을 요청하고, 그 결과들을 프락시에서 집약한 다은 클라이언트에 응답하는 구성을 취한다.
리소스로는 크게 아래 4가지를 개발하며 REST API 서버로 구축한다.
- 프락시: 추론기로의 접근을 중개, 추론 결과를 집약
- setosa 추론기: setosa와 그 외로 이진 분류. 라벨은 0=setosa, 1=그외
- versicolor 추론기: versicolor와 그 외로 이진 분류. 라벨은 0=versicolor, 1=그외
- virginica 추론기: virginica와 그 외로 이진 분류. 라벨은 0=virginica, 1=그외
프락시는 클라이언트의 요청을 받아 그 내용을 전 푸론기로 보낸다. 추론기의 입장에서는 프락시가 클라이언트가 된다.
프락시는 FastAPI로 기동하고, 프락시에서 추론기로의 요청에는 httpx라고 하는 파이썬의 웹 클라이언트 라이브러리를 사용한다. httpx란 파이썬에서 범용적으로 사용되는 requests라고 하는 웹 클라이언트의 후속 버전으로, 비동기 요청이나 HTTP/2를 지원한다. 여러 추론을 효율적으로 수행하기 위해서 httpx의 asyncio를 통해 비동기적으로 요청을 실행한다.
src/api_composition_proxy/routers/routers.py
import asyncio
import logging
import uuid
from typing import Any, Dict, List
import httpx
from fastapi import APIRouter
from pydantic import BaseModel
from src.api_composition_proxy.configurations import ServiceConfigurations
logger = logging.getLogger(__name__)
router = APIRouter()
class Data(BaseModel):
data: List[List[float]] = [[5.1, 3.5, 1.4, 0.2]]
@router.get("/health")
def health() -> Dict[str, str]:
return {"health": "ok"}
@router.get("/metadata")
def metadata() -> Dict[str, Any]:
return {
"data_type": "float32",
"data_structure": "(1,4)",
"data_sample": Data().data,
"prediction_type": "float32",
"prediction_structure": "(1,2)",
"prediction_sample": {
"service_setosa": [0.970000, 0.030000],
"service_versicolor": [0.970000, 0.030000],
"service_virginica": [0.970000, 0.030000],
},
}
# 전 추론기에 대한 health check
@router.get("/health/all")
async def health_all() -> Dict[str, Any]:
logger.info(f"GET redirect to: /health")
results = {}
async with httpx.AsyncClient() as ac:
async def req(ac, service, url):
response = await ac.get(f"{url}/health") # url : 추론기의 엔드포인트
return service, response
tasks = [req(ac, service, url) for service, url in ServiceConfigurations.services.items()]
responses = await asyncio.gather(*tasks)
for service, response in responses:
results[service] = response.json()
return results
@router.get("/predict/get/test")
async def predict_get_test() -> Dict[str, Any]:
job_id = str(uuid.uuid4())[:6]
logger.info(f"TEST GET redirect to: /predict/test as {job_id}")
results = {}
async with httpx.AsyncClient() as ac:
async def req(ac, service, url, job_id):
response = await ac.get(f"{url}/predict/test", params={"id": job_id})
return service, response # string, response
tasks = [req(ac, service, url, job_id) for service, url in ServiceConfigurations.services.item()]
responses = await asyncio.gather(*tasks)
for service, response in responses:
logger.info(f"{service} {job_id} {response.json()}")
results[service] = response.json()
return results
@router.post("/predict/post/test")
async def predict_post_test() -> Dict[str, Any]:
job_id = str(uuid.uuid4())[:6]
logger.info(f"TEST POST redirect to: /predict as {job_id}")
results = {}
async with httpx.AsyncClient() as ac:
async def req(ac, service, url, job_id):
response = await ac.post(f"{url}/predict", json={"data": Data().data}, params={"id": job_id})
return service, response
tasks = [req(ac, service, url, job_id) for service, url in ServiceConfigurations.services.items()]
responses = await asyncio.gather(*tasks)
for service, response in responses:
logger.info(f"{service} {job_id} {response.json()}")
results[service] = response.json()
return results
# 전 추론기에 요청
@router.post("/predict")
async def predict(data: Data) -> Dict[str, Any]:
job_id = str(uuid.uuid4())[:6]
logger.info(f"POST redirect to: /predict as {job_id}")
results = {}
async with httpx.AsyncClient() as ac:
async def req(ac, service, url, job_id, data):
response = await ac.post(f"{url}/predict", json={"data": data.data}, params={"id": job_id})
return service, response
tasks = [req(ac, service, url, job_id, data) for service, url in ServiceConfigurations.services.items()]
responses = await asyncio.gather(*tasks)
for service, response in responses:
logger.info(f"{service} {job_id} {response.json()}")
results[service] = response.json()
return results
# 전 추론기에 요청하고, 추론결과를 집약
# 가장 확률이 높은 결과를 클라이언트에게 응답
@router.post("/predict/label")
async def predict_label(data: Data) -> Dict[str, Any]:
job_id = str(uuid.uuid4())[:6]
logger.info(f"POST redirect to: /predict as {job_id}")
results = {"prediction": {"proba": -1.0, "label": None}}
async with httpx.AsyncClient() as ac:
async def req(ac, service, url, job_id, data):
response = await ac.post(f"{url}/predict", json={"data": data.data}, params={"id": job_id})
return service, response
tasks = [req(ac, service, url, job_id, data) for service, url in ServiceConfigurations.services.items()]
responses = await asyncio.gather(*tasks)
for service, response in responses:
logger.info(f"{service} {job_id} {response.json()}")
proba = response.json()["prediction"][0]
if results["prediction"]["proba"] < proba:
results["prediction"] = {"proba": proba, "label": service}
return results- /predict와 /predict/label은 요청된 데이터에 대한 추론으로, 모두 httpx로 추론기에 대해 POST 요청을 수행하고 추론 결과를 얻는 구성이다.
- /predict 엔드포인트는 각 추론기의 binary classification 결과를 응답하며 /predict/label 엔드포인트에서는 각 추론기가 수행한 이진 분류 결과를 집약하고, 가장 확률이 높은 클래스를 응답하도록 되어있다.
src/app/routers/routers.py
- 각 추론기도 마찬가지로 FastAPI로 구현되어있으며 웹 싱글 패턴에서 구현한 것과 같기 때문에 코드는 생략한다.
- 각 추론기에서는 미리 저장된 ONNX모델을 onnxruntime으로 Inference를 수행한다.
docker-compose.yml
version: "3"
services:
proxy:
container_name: proxy
image: tjems6498/ml-system-in-actions:horizontal_microservice_pattern_proxy_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- APP_NAME=src.api_composition_proxy.app.proxy:app
- PORT=9000
- SERVICE_SETOSA=service_setosa:8000
- SERVICE_VERSICOLOR=service_versicolor:8001
- SERVICE_VIRGINICA=service_virginica:8002
ports:
- "9000:9000"
command: ./run.sh
depends_on:
- service_setosa
- service_versicolor
- service_virginica
service_setosa:
container_name: service_setosa
image: tjems6498/ml-system-in-actions:horizontal_microservice_pattern_setosa_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- PORT=8000
- MODE=setosa
ports:
- "8000:8000"
command: ./run.sh
service_versicolor:
container_name: service_versicolor
image: tjems6498/ml-system-in-actions:horizontal_microservice_pattern_versicolor_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- PORT=8001
- MODE=versicolor
ports:
- "8001:8001"
command: ./run.sh
service_virginica:
container_name: service_virginica
image: tjems6498/ml-system-in-actions:horizontal_microservice_pattern_virginica_0.0.1
restart: always
environment:
- PLATFORM=docker_compose
- PORT=8002
- MODE=virginica
ports:
- "8002:8002"
command: ./run.sh- 병렬 마이크로서비스 패턴은 4가지의 컴포넌트(프락시, setosa추론기, vericolor추론기, virginica추론기)가 개별적으로 배포되어야 하기 때문에 도커 컴포즈로 가동한다.
- 프락시의 환경변수를 보면 추론기의 엔드포인트를 각각 저장하는 것을 알 수 있고 이를 프락시 routers.py 의 ServiceConfigurations.services.items() 에서 활용하게 된다.
- 각 추론기는 MODE라는 환경변수를 통해 모델을 load할때 사용할 모델의 경로를 얻게된다. (src/configurations.py)
- 프락시를 9000번 포트로 기동하고 각 추론기는 8000~8002번 포트로 공개한다.
이제 도커 컴포즈를 통해 각 컨테이너를 실행하고 클라이언트에서 프락시에 결과를 요청해보자.
# 컨테이너 가동
docker-compose -f ./docker-compose.yml up -d
# /predict에 요청
curl \
-X POST \
-H "Content-Type: application/json" \
-d '{"data": [[1.0, 2.0, 3.0, 4.0]]}' \
localhost:9000/predict
# {
# "setosa": {
# "prediction": [
# 0.2897033989429474,
# 0.710296630859375
# ]
# },
# "virginica": {
# "prediction": [
# 0.3042130172252655,
# 0.6957869529724121
# ]
# },
# "versicolor": {
# "prediction": [
# 0.05282164365053177,
# 0.9471783638000488
# ]
# }
# }
# /predict/label에 요청
curl \
-X POST \
-H "Content-Type: application/json" \
-d '{"data": [[1.0, 2.0, 3.0, 4.0]]}' \
localhost:9000/predict/label
# {
# "prediction": {
# "proba": 0.3042130172252655,
# "label": "virginica"
# }
# }- 프락시에서 추론기로 요청할때 비동기처리로 인해 input 데이터가 동시에 각각의 추론기에 들어가 추론이 일어나게 되고 그 결과를 response 한다.
- /predict 에서는 각 추론기의 결과를 모두 응답하고 /predict/label 에서는 가장 확률이 높은 클래스의 확률값과 라벨을 응답한다.
5. 이점
- 추론 서버를 분할하여 리소스의 조정과 장애 분리가 가능하다.
- 추론 워크플로 사이에 의존관계를 두지 않으면서도 유연한 시스템 구축이 가능하다.
- 같은 데이터를 여러 추론기에서 동시에 추론하도록 비동기처리하여 효율적으로 운영할 수 있다.
6. 검토사항
병렬 MSA 패턴을 구축할 때의 주의사항 중 하나는 동기적으로 추론할지, 비동기적으로 추론할지를 결정하는 것이다. 동기 추론 패턴과 비동기 추론 패턴의 차이를 생각해보면 동기와 비동기는 시스템의 용도나 workflow에 따라 결정하는 것이 옳다.
먼저, 동기적으로 추론할 경우 병렬 MSA 패턴에서는 Timeout이 중요하다. 여러 개의 추론기로 추론을 수행하는 이상, 한 개라도 느린 추론기가 있으면 전체 추론속도는 가장 느린 추론기의 지연속도를 가지게 된다. 아무리 속도가 빠른 추론기가 있어도 클라이언트 측에 대기시간에 관한 서비스 수준이 정해져 있고 이 대기시간 이내에 응답할 수 없다면 의미가 없다.
이 경우 Timeout의 설정 전략으로 두가지 패턴이 존재한다. 첫 번째는 전체 추론에 대해 Timeout을 설정하는 all or nothing 패턴이다. 추론결과를 응답하거나 Timeout으로 응답하지 않거나 둘중 하나다. 두 번째 패턴은 각 추론기에 대한 요청에 Timeout을 설정하고, 대기시간 이내에 추론된 것만 클라이언트에게 응답하는 패턴이다. 느린 추론기의 추론을 끝까지 기다리지 않으면서 나머지 추론 결과들을 응답할 수 있다. 단, 추론 결과들 사이에 관계성이 있고 반드시 집계가 필요한 구조라면 이 패턴은 성립할 수 없다.
비동기적으로 추론하는 경우, 추론기의 속도로 추론의 우열을 결정하는 구성을 취하면 느리더라도 유익한 추론을 하는 추론기는 활용되지 못할 가능성이 있다. 동기적으로 처리하는 병렬 MSA 패턴과 마찬가지로, 추론기의 지연시간 차이에는 주의가 필요하다.
END
병렬 마이크로서비스 패턴은 여러 개의 추론기를 조합하기 때문에 시스템이 복잡해질 가능성이 있다. 프락시에서 추론기 서비스의 추가, 삭제나 응답 로직을 제어한다고 했지만 추론기의 수가 늘어나 로직이 복잡해지면 운용 측면에서 효율은 떨어지기 마련이다. 나아가 운용상 실수로 장애가 발생할 리스크도 높아질 것이기 때문에 구조가 복잡해질 것 같은 상황에서는 또 다른 프락시를 만들어 엔드포인트를 분할하는 방식도 고려해 볼 수 있을 것 같다.
Keep Going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter4_serving_patterns/horizontal_microservice_pattern
My Code: https://github.com/tjems6498/MLOps-DP/tree/main/serving_patterns/horizontal_microservice_pattern
'MLOps' 카테고리의 다른 글
| Kubeflow pipeline에서 DVC로 데이터 버전관리하기 (0) | 2022.12.23 |
|---|---|
| [ML Design Pattern] 추론 시스템 / 7. 시간차 추론 패턴 (1) | 2022.12.22 |
| [ML Design Pattern] 추론 시스템 / 5. 전처리 · 추론 패턴 (0) | 2022.12.05 |
| [ML Design Pattern] 추론 시스템 / 4. 배치 추론 패턴 (0) | 2022.11.10 |
| [ML Design Pattern] 추론 시스템 / 3. 비동기 추론 패턴 (0) | 2022.11.03 |
