mAP(Mean Average Precision)
저번 mAP(Mean Average Precision) [1] : visionhong.tistory.com/5 포스팅 에서는 MAP를 알기위해 필요한 지식에 대해 주로 다루었고 이번 포스팅에서는 MAP계산 과정을 실제 코드와 함께 알아보자.
Review

우선 강아지라는 1개의 클래스에 대해서만 생각해보자. mAP를 계산하기 위해서는 prediction box와 test set의 ground truth가 필요하다. 3개의 이미지에는 4개의 Ground truth가 있으며 7개의 prediction이 confidence와 함께 주어진다.
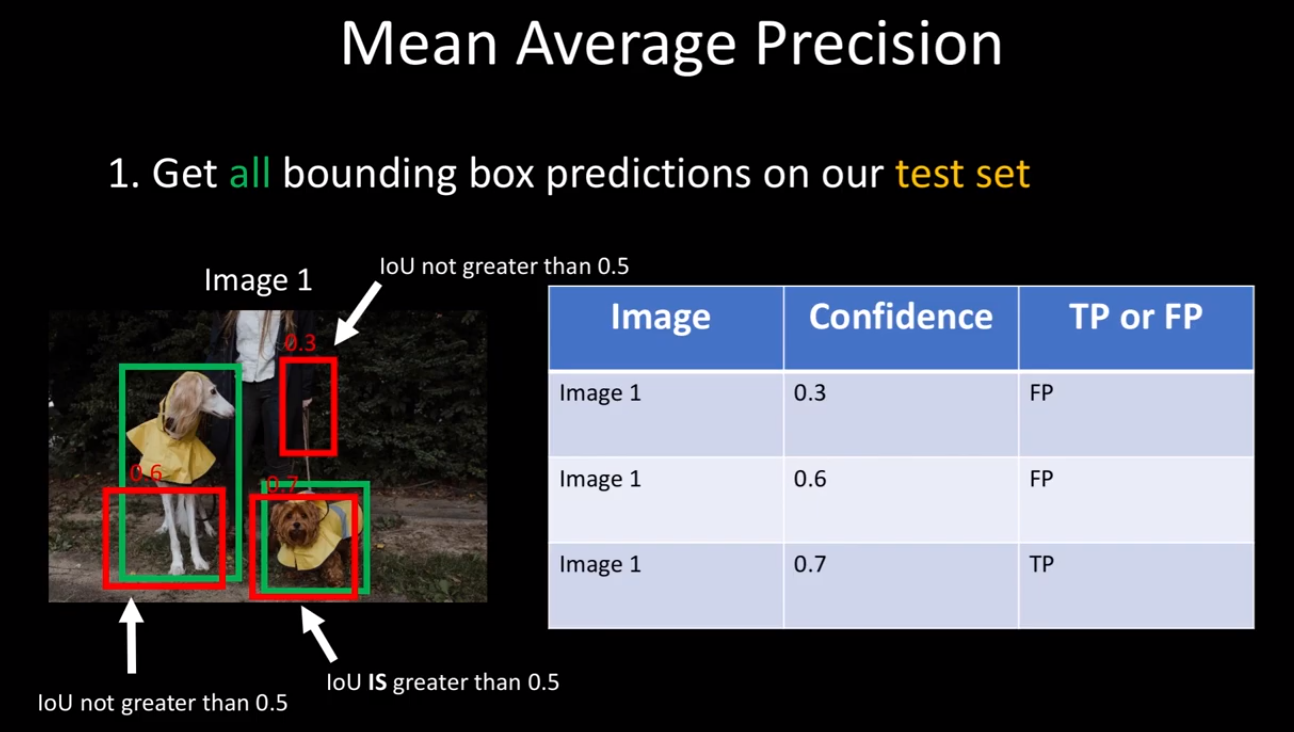

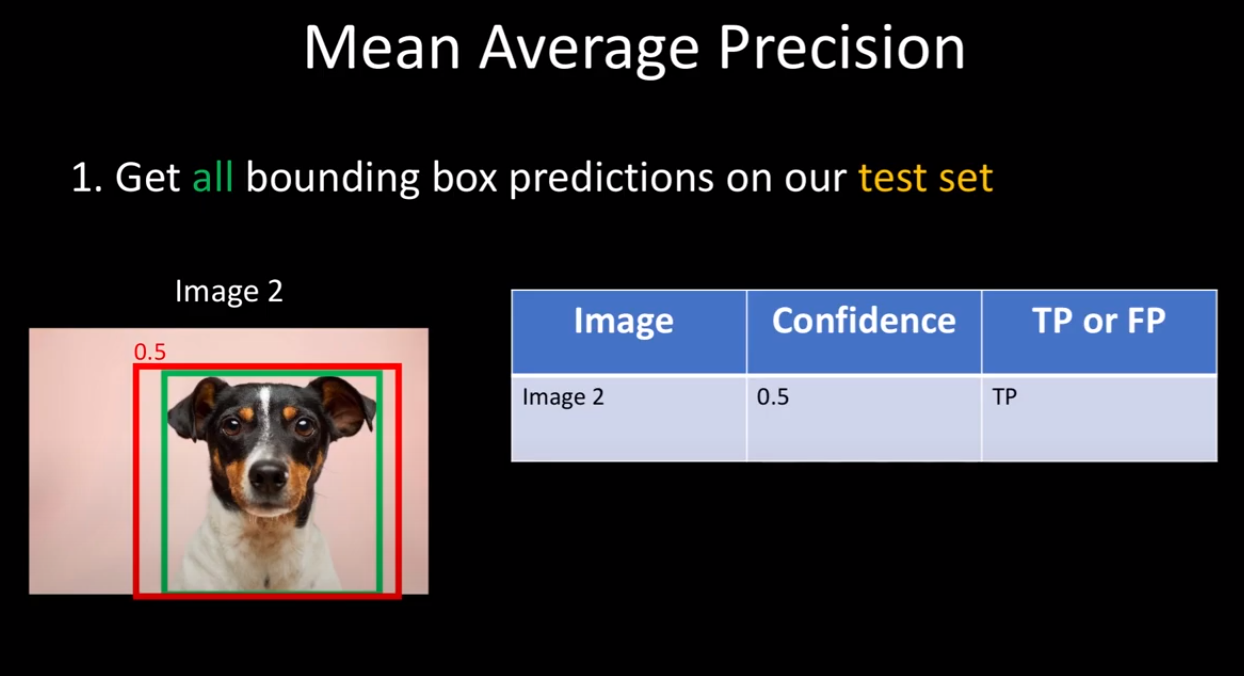
그리고 각 이미지에 대해 ground truth와 prediction의 IOU가 0.5 이상인 것은 TP(True Positive) 이하인 것은 FP(False Positive)로 정한다.
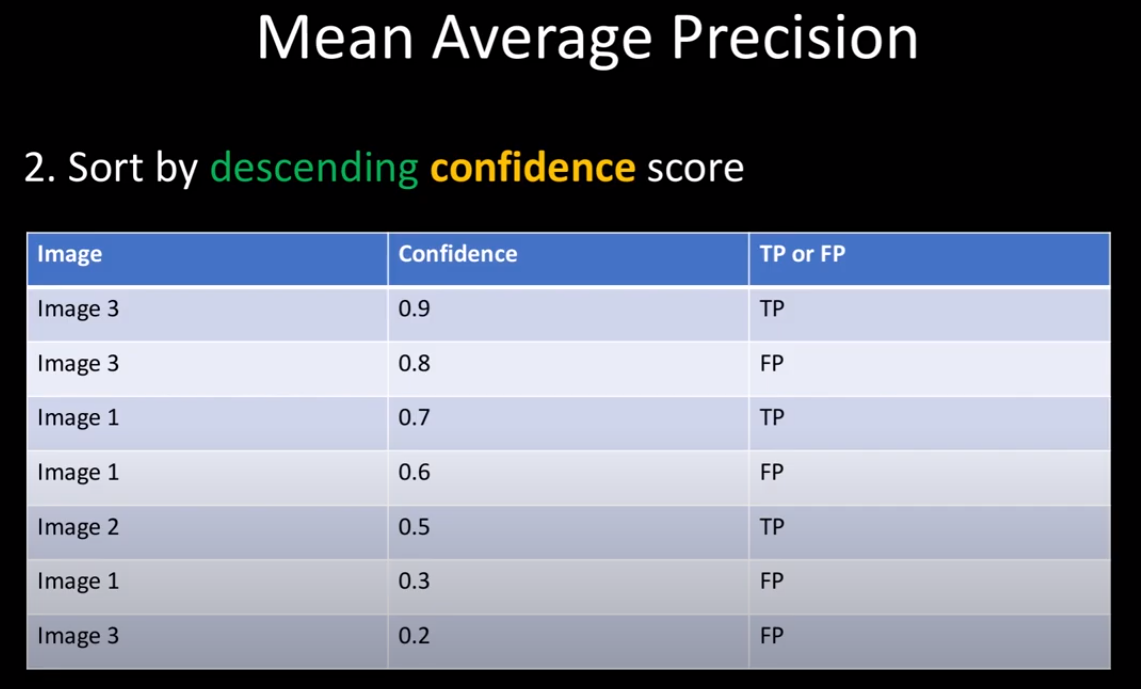
모든 prediction에 대한 TP or FP를 정했으면 confidence가 높은 순으로 정렬을 한다. (정렬을 하는 정확한 이유는 찾을 수 없었는데 내 생각으로는 나중에 Precision-Recall 그래프의 모양이 너무 구겨지지 않도록 하기 위해서 사용하는 것 같다. -> confidence가 높을수록 TP일 확률이 높기 때문에)
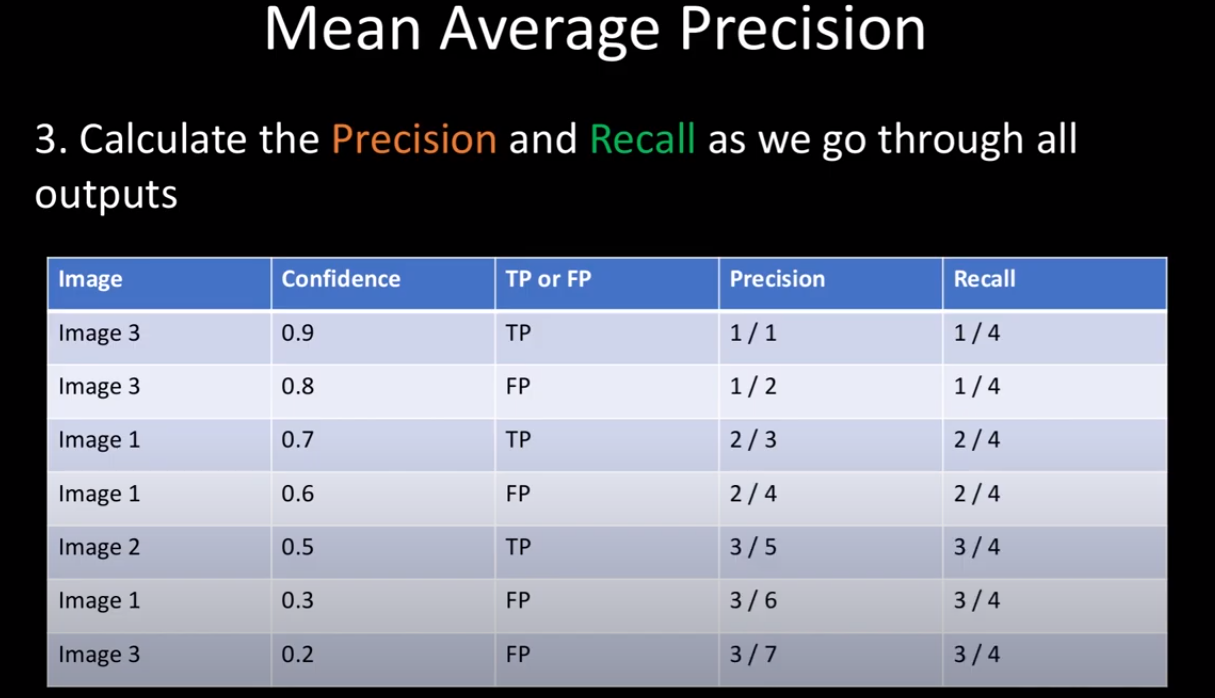
7개의 prediction의 Precision과 Recall에 대해 계산을 한다. (계산 방법은 mAP(Mean Average Precision) [1] 포스팅에 자세히 나와있다.)
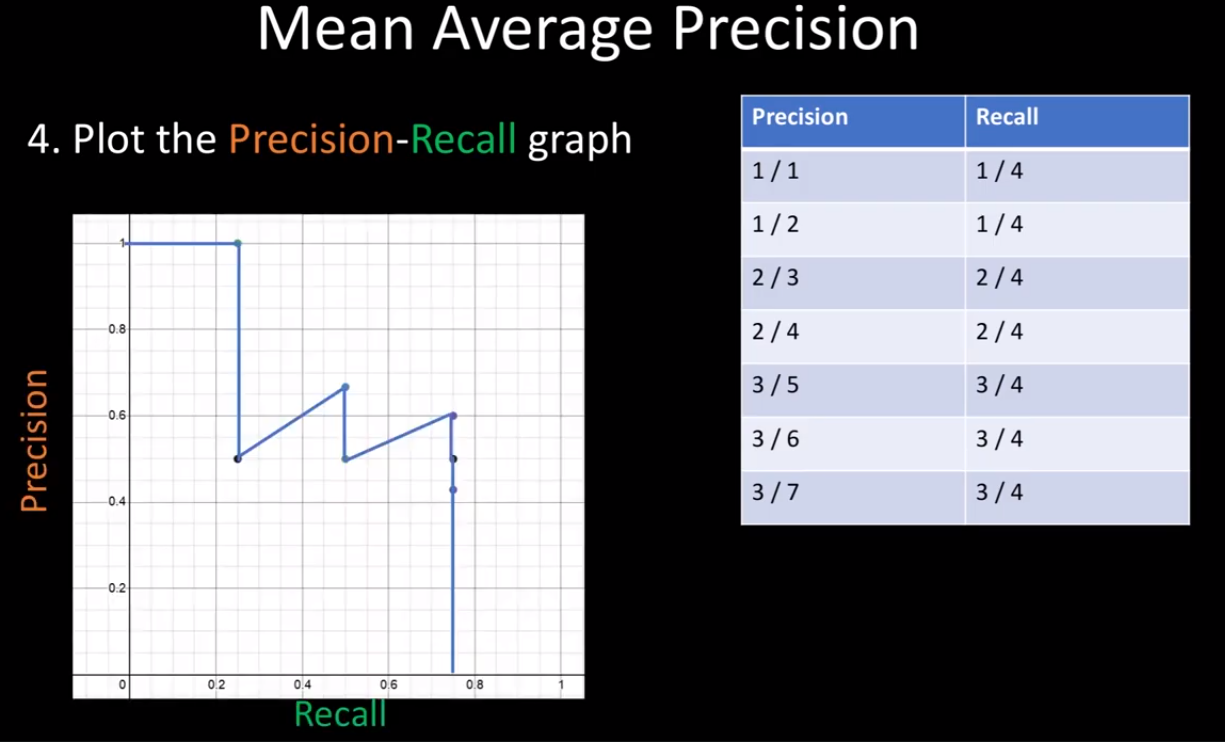
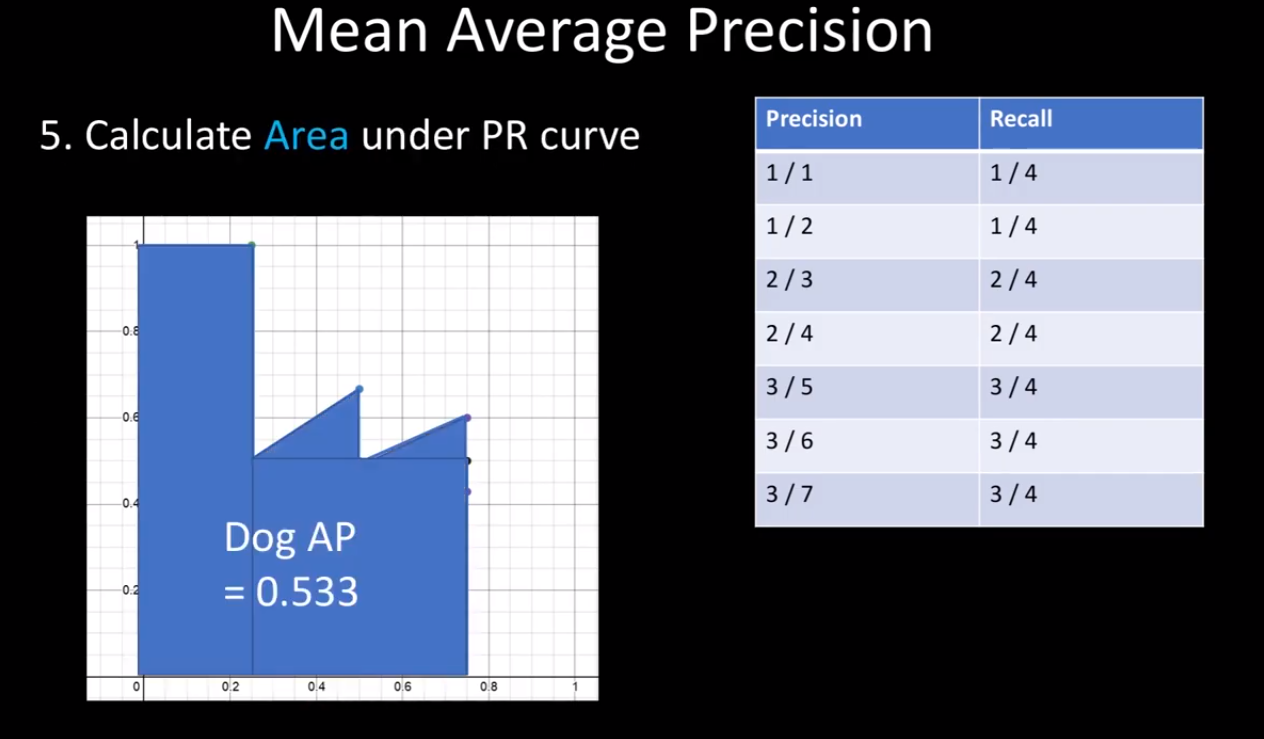
이렇게 Precision-Recall 그래프를 그린 후 아래 면적을 통해 강아지의 AP를 얻을 수 있다.

해당 과정을 통해 모든 class에 대해 AP를 구한 후에 그것을 평균을 내면 mAP를 얻을 수 있다.

여러 Object Detection 논문을 보면 알 수 있듯이 단지 IOU 0.5 만을 기준으로 mAP를 계산하지 않고 0.5~0.95 사이의 IOU까지 0.5씩 올려가면서 성능결과를 제시한다. (코드에서는 0.5에 대한 mAP 계산을 할 예정.)
지금까지 mAP를 구하는 과정을 살펴 보았고 이제 implementation을 해보자
코드구현
import torch
from collections import Counter
def mean_average_precision(pred_boxes, true_boxes, iou_threshold=0.5, box_format='corners', num_classes=20):
# pred_boxes (list): [[train_idx(image_num), class_pred, prob_score, x1, y1, x2, y2], ...]
average_precisions = [] # 각 클래스별로 AP가 추가될 리스트
epsilon = 1e-6 # stability numeric
for c in range(num_classes):
detections = [] # 각 클래스의 detection이 담길 리스트
ground_truths = [] # 각 클래스의 ground truth가 담길 리스트
for detection in pred_boxes:
if detection[1] == c:
detections.append(detection)
for true_box in true_boxes:
if true_box[1] == c:
ground_truths.append(true_box)
# img 0 has 3 bboxes
# img 1 has 5 bboxes
# amount_bboxes = {0:3, 1:5}
amount_bboxes = Counter(gt[0] for gt in ground_truths) # gt의 각 이미지(key)의 개수(value)를 셈
for key, val in amount_bboxes.items():
amount_bboxes[key] = torch.zeros(val) # 개수를 1차원 tensor로 변환
# amount_boxes = {0: torch.tensor([0,0,0]), 1:torch.tensor([0,0,0,0,0])}
detections.sort(key=lambda x: x[2], reverse=True) # detections의 confidence가 높은 순으로 정렬
TP = torch.zeros((len(detections))) # detections 개수만큼 1차원 TP tensor를 초기화
FP = torch.zeros((len(detections))) # 마찬가지로 1차원 FP tensor 초기화
total_true_bboxes = len(ground_truths) # recall의 TP+FN으로 사용됨
for detection_idx, detection in enumerate(detections): # 정렬한 detections를 하나씩 뽑음
# ground_truth_img : detection과 같은 이미지의 ground truth bbox들을 가져옴
ground_truth_img = [bbox for bbox in ground_truths if bbox[0] == detection[0]]
best_iou = 0 # 초기화
for idx, gt in enumerate(ground_truth_img): # 현재 detection box를 이미지의 ground truth들과 비교
iou = intersection_over_union(
torch.Tensor(detection[3:]).view(1,-1),
torch.Tensor(gt[3:]).view(1,-1),
box_format=box_format)
if iou > best_iou: #ground truth들과의 iou중 가장 높은놈의 iou를 저장
best_iou = iou
best_gt_idx = idx # 인덱스도 저장
if best_iou > iou_threshold: # 그 iou가 0.5 이상이면 헤당 인덱스에 TP = 1 저장, 이하면 FP = 1 저장
if amount_bboxes[detection[0]][best_gt_idx] == 0:
TP[detection_idx] = 1
amount_bboxes[detection[0]][best_gt_idx] = 1
else:
FP[detection_idx] = 1 # 이미 해당 물체를 detect한 물체가 있다면 즉 인덱스 자리에 이미 TP가 1이라면 FP=1적용
else:
FP[detection_idx] = 1
# [1, 1, 0, 1, 0] -> [1, 2, 2, 3, 3]
TP_cumsum = torch.cumsum(TP, dim=0)
FP_cumsum = torch.cumsum(FP, dim=0)
recalls = TP_cumsum / (total_true_bboxes + epsilon)
precisions = torch.divide(TP_cumsum, (TP_cumsum + FP_cumsum + epsilon)) # TP_cumsum + FP_cumsum을 하면 1씩 증가하게됨
recalls = torch.cat((torch.tensor([0]), recalls)) # x축의 시작은 0 이므로 맨앞에 0추가
precisions = torch.cat((torch.tensor([1]), precisions)) # y축의 시작은 1 이므로 맨앞에 1 추가
average_precisions.append(torch.trapz(precisions, recalls)) # 현재 클래스에 대해 AP를 계산해줌
return sum(average_precisions) / len(average_precisions) # MAP
Ending
이번 포스팅에서는 mAP의 계산과정과 그 코드를 함께 살펴보았다. 모든 Object Detection 모델의 성능평가는 mAP로 하기 때문에 반드시 알아야 하는 개념이다.
reference : www.youtube.com/watch?v=FppOzcDvaDI&t=1s
'Deep Learning' 카테고리의 다른 글
| Linear Regression (1) | 2021.01.26 |
|---|---|
| [논문리뷰] SSD : Single Shot Multibox Detector (2) | 2021.01.23 |
| NMS(Non Max Suppression) (2) | 2021.01.21 |
| IOU(Intersection over union) (0) | 2021.01.20 |
| [논문리뷰] MobileNets V1 (0) | 2021.01.04 |
