Training data-efficient image transformers & distillation through attention
Hugo Touvron / Matthieu Cord / Matthijs Douze / Francisco Massa / Alexandre Sablayrolles / Herve Jegou
Facebook AI and Sorbonne University
이번 포스팅에서는 2020년 12월에 Facebook AI에서 발표한 DeiT라는 논문에 대해 리뷰하려고 한다. 이 논문에서는 Vision Transformer(ViT)가 당시 SOTA를 달성했지만 JFT-300M 데이터셋을 pretrain에서 쓰고 ImageNet으로 finetuning을 하면서 엄청나게 많은 데이터셋을 사용했다는 점을 지적한다. JFT 데이터셋은 오픈되지 않은 구글만의 데이터셋이며 ViT의 학습시간도 길기때문에 이 논문에서는 ViT모델을 유지한채 학습방법을 조금 달리해서 오로지 ImageNet 데이터셋과 single 8-GPU만으로 2~3일만에 학습하고 그에 준하는 Performance를 얻을 수 있다고 이야기 한다.
또한 Knowledge Distillation과 Distillation token을 추가했는데 DieT에 대해 자세히 알아보자.
+ 본 논문은 ViT의 모델을 그대로 가져가기 때문에 모델에 대한 설명은 넘어가고 새로 추가한 내용들만 다룰 것이다.
Introduction
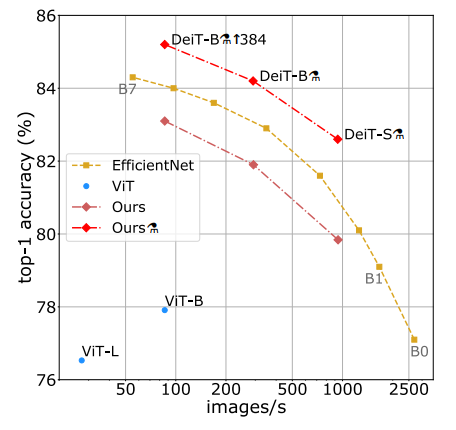
- 논문에서는 먼저 accuracy & speed trade-off 그래프를 보여주면서 DieT의 성능을 보여준다.
- 그래프의 점은 우측 상단에 있을수록 좋은 모델이고 여기서 가장 중요하게 볼 부분이 ViT와 DeiT와의 차이이다.
- 여기서 ViT-B는 SOTA ViT모델이 아니라 ImageNet 데이터만으로 학습했을때의 ViT 모델인데 이 모델과 DeiT-B와는 꽤 많은 성능차이가 나는 것을 볼 수 있다.
- DeiT-B 옆에있는 증류기 기호는 Distillation 학습방법을 사용한 모델에 붙는 기호인데 이에 대해서는 아래에서 다시 다룰것이다.
전반적인 내용 요약
- 오직 ImageNet dataset으로 CNN layer없이 SOTA 모델들과 경쟁할 수 있으며 적은 GPU로 빠른 학습이 가능하다. 또한 DeiT-S / DeiT-Ti 모델은 ResNet50 / ResNet18 과 비슷한 적은 파라미터를 가진다.
- ViT의 class token과 똑같은 방식으로 distillation token을 추가하여 따로 학습할 수 있도록 하였고 이것은 나중에 teacher model의 output과 비교하는데에 사용된다.
- knowledge distillation을 할때 teacher 모델을 Transformer로 사용하는것보다 CNN 기반 모델을 사용하는것이 더 좋은 성능을 낸다. -> coz of inductive bias
- differnt downstream task 에서도 충분히 좋은 성능을 낼 수 있다. (CIFAR10, CIFAR100, Oxford-102 flowers 등)
Knowledge Distillation
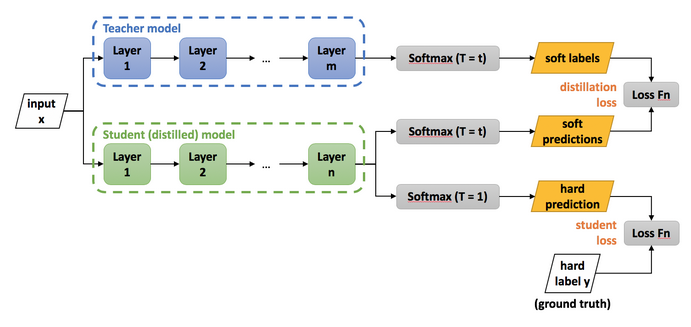
Knowledge Distillation이란 student model이 teacher model과 비슷한 성능을 낼 수 있도록, 학습과정에서 큰 teacher model의 지식을 student network에 전달하여 student network의 성능을 높이려는 목적을 가진다.
Knowledge Distillation은 위 그림과 같이 Soft dillation으로 많이 사용하는데 먼저 soft dillation에 대해 알아보자.

- soft distillation은 위와 같은 식으로 표현할 수 있다. 왼쪽항은 student model의 output과 true label과의 cross entropy를 구하고 오른쪽 항은 student와 teacher의 softmax값을 smoothing 해서 KL divergence를 구한다.
- λ : 왼쪽항과 오른쪽 항의 중요도를 가르는 가중치
- τ : softmax값을 soft하게 바꿔주는 일종의 smoothing 역할 (ex) 0.98, 0.01, 0.01 -> 0.80, 0.10, 0.10)
- Ψ : softmax
- KL : Kullback-Leibler divergence는 두 확률분포의 차이를 수치적으로 나타내는 값을 의미하며 정답과 예측에 대한 두개의 확률 분포의 Cross Entropy - true분포에 대한 Entropy(정보량)로 구한다. 즉 true 분포와 비교해서 상대적으로 얼마나 정보량의 차이가 나는지를 의미하기 때문에 relative entropy라고도 한다.
- KL divergence의 특징 1. 0보다 크다. 2. KL(P||Q) != KL(Q||P)이다.
본 논문에서는 soft distillation말고 hard distillation에 대해서도 실험을 한다.

- hard distillation은 위와같이 나타내며 왼쪽항은 student model output과 true label간의 cross entropy를 구하고 오른쪽 항은 student model output과 teacher model output의 argmax하여 얻은 encoding된 hard한 값(yt)과의 cross entropy를 구한다.
- soft distillation의 λ와 τ가 없어졌기 때문에 하이퍼 파라미터로부터 자유롭고 이 hard distiilation 또한 ε을 통해서label smoothing을 시킬 수있다.
soft distillation과 hard distillation에 대한 성능평가는 뒤에서 다시 언급할 것이다.
Distillation Token
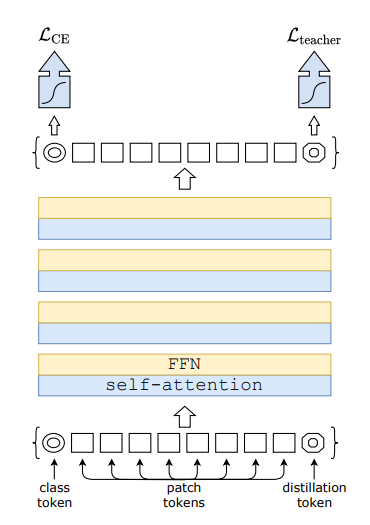
- DeiT에서는 ViT에서의 class token과 똑같은 방식으로 distillation token이라는 것을 모델 앞부분에 붙여서 실험을 한다.
- class token이 classification을 위한 embedding dim이 되는것 처럼 distillation token이 embedding 상태인 마지막 레이어에서 teacher model의 output과 cross entropy를 통해 학습을 하도록 만들어 주었다.
- 여기서 논문에서는 학습을 진행했을때 class token과 distillation token의 코사인 유사도가 0.06이었는데 맨 마지막 embedding 상태에서는 0.93의 코사인 유사도가 나왔다고 한다. 즉 class token과 teacher model의 영향을 받는 distillation token은 비슷한 output을 내지만 같은 결과를 내는것은 아니라는 것이다.
- 여기서 distillation token이 teacher model의 영향을 받는다는 의미는 예를들어 고양이가 구석에 있는 이미지에서 crop과 같은 data augmentation을 하면 자칫 물체가 없는 곳을 crop 할 수 있고 이에대해 true label은 그대로 고양이 이지만 teacher model의 output은 고양이라고 하지 않아서 distillation token과 class token이 조금은 다르게 학습이 된다는 것을 말한다.
Experiments

먼저 DeiT 모델의 크기에 따른 하이퍼 파라미터이다. Base model이 86M로 가장 크며 interpolate방식으로 파라미터 값들을 줄이는 방식을 택했다. (ViT와 동일)
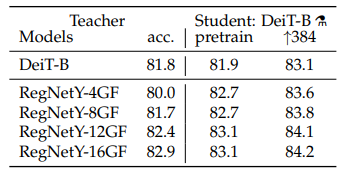
Teacher model을 DeiT-B자신으로 사용하는것보다 CNN 기반 model로 사용했을때 accuracy가 더 높은것을 볼 수 있다. 그 이유는 ViT에서 언급했던 것처럼 CNN기반 모델은 inductive bias(translation equivariance 및 locality)가 있기 때문에 특징을 추출하는데에 엄청나게 많은 데이터 없이 학습이 잘 되고 이러한 teacher모델을 두고 있다면 inductive bias가 자유로운 transformer에게도 도움을 주기 때문이라고 한다.
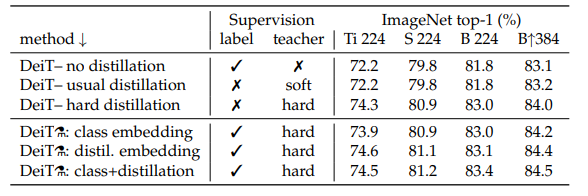
위 표는 위쪽이 no distillation, soft distillation, hard distillation에 대한 성능비교이고 아래쪽이 distillation token과 관련된 성능 비교이다. hard distillation을 사용하고 distillation token을 사용했을때 accuracy가 가장 높은 것을 알 수 있다.
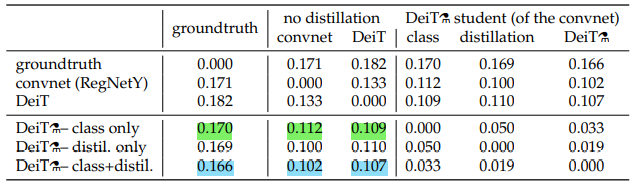
위 표는 class token만 가지고 distillation을 했을때 convnet 보다 transformer에 더 가까운 상관관계를 지니고(초록색) class token과 distillation token을 가지고 distillation을 했을때 ctransformer보다 convnet에 더 가까운 상관관계를 지닌다는 것을 보여준다.(파란색)
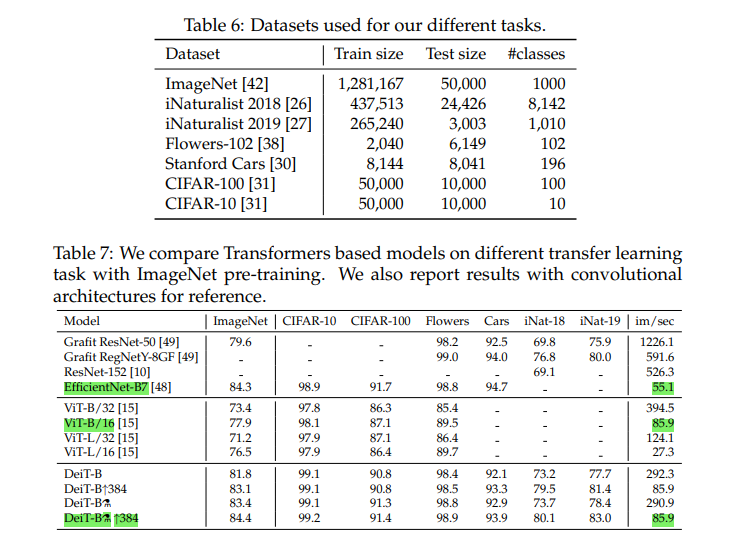
초반부에 말한것 처럼 다른 task의 dataset에서도 충분히 competitive한 성능을 보여준다.
Training details & ablation
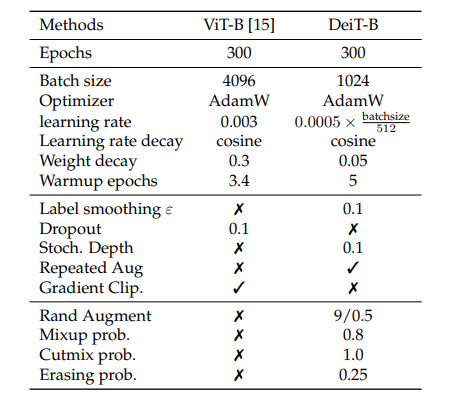
위와같이 DeiT는 ViT와 약간 다른 하이퍼파라미터와 Augmentation 기법을 적용하였다. 어찌됐든 Transformer 기반 모델들은 많은 양의 데이터가 필요하기 때문에 extensive한 data augmentation이 필요하다고 말하고 여기에 사용한 대부분의 data augmentation이 모두 효과가 있었다고 한다.
그런데 여기서 내가 아직 모르고 있던 Augmentation이 있었는데 바로 Repeated Augmenation이다.
Batch Augmentation and Repeated Augmentation
Batch Augmentation
- 배치안에 있는 모두 다른 이미지들을 한번만 Augmentation하지 말고 현재 배치사이즈에 있는 이미지에 대해 여러번 Augmentation 해서 사용하면 모델을 더 잘 일반화 시킬 수 있다고 해당 논문에서 주장한다. 예를들어 배치사이즈가 16일때 이미지를 4번씩 Augmentation을 하게되면 이때 배치사이즈는 16 x 4 = 64 가 된다.
Repeated Augmentation
- 배치 내에서 하나의 이미지를 여러번 Augmentation한다는 의미로는 Batch Augmentation과 같지만 Batch Augmentation은 그만큼 배치사이즈가 늘어난다면 Repeated Augmentation은 기존 배치사이즈가 64일때 independent한 이미지 64장을 16장으로 줄이고 그것을 장당 4번씩 Augmentation 하게된다.
- 이렇게 되면 sample들이 독립적이지 않기 때문에 오히려 성능이 떨어지는데 배치사이즈 커지게 되면 오히려 배치내의 이미지가 independent할 때 보다 성능이 좋아진다고 한다. (왜 그런지는 논문을 직접 읽어봐야 할 것 같다.)
PyTorch Implementation
Model
import torch
import torch.nn as nn
from functools import partial
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.layers import trunc_normal_
class DistillationVisionTransformer(VisionTransformer):
def __init__(self, *args, **kwargs):
super(DistillationVisionTransformer, self).__init__()
# new : distillation token
self.dist_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim)) # (n_samples, token_dim, embed_dim)
num_patches = self.patch_embed.num_patches # 패치의 개수 ex) 384x384 with 16 patch_size -> 576개
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 2, self.embed_dim))
# new : distillation classifier(head)
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if self.num_classes > 0 else nn.Identity()
# initialize
trunc_normal_(self.dist_token, std=.02) # mean = 0 / std = 0.02
trunc_normal_(self.pos_embed, std=.02)
self.head_dist.apply(self._init_weights)
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_token = self.cls_token.expand(B, -1, -1) # 배치사이즈만큼 확장
dist_token = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_token, dist_token, x), dim=1) # concatenate cls_token, dist_token, x 순
x = x + self.pos_embed # positional embedding
x = self.pos_drop(x) # use dropout if we need
for block in self.blocks: # encoder (multi-head-attention + mlp)
x = block(x)
x = self.norm(x) # Layer Normalization
return x[:, 0], x[:, 1] # cls_embedding, dist_embedding
def forward(self, x):
x, x_dist = self.forward_features(x) # cls, dist
x = self.head(x) # cls classifier
x_dist = self.head_dist(x_dist) # dist classifier
if self.training:
return x, x_dist
else:
return (x + x_dist / 2) # mean- DeiT는 ViT의 구조를 그대로 가져오고 distillation token만 추가했기 때문에 timm 모듈의 Vision Transformer를 상속받아서 구현했다.
- 마지막에보면 training일때만 cls와 dist를 return하는 것으로 보아 학습시에만 distillation loss를 사용하는 것 같다.
Loss
import torch
from torch.nn import functional as F
class DistillationLoss(torch.nn.Module):
def __init__(self, base_criterion: torch.nn.Module, teacher_model: torch.nn.Module,
distillation_type: str, alpha: float, tau: float):
super(DistillationLoss, self).__init__()
self.base_criterion = base_criterion
self.teacher_model = teacher_model
assert distillation_type in ['none', 'soft', 'hard']
self.distillation_type = distillation_type
self.alpha = alpha
self.tau = tau
def forward(self, inputs, outputs, labels):
outputs_kd = None
if not isinstance(outputs, torch.Tensor):# outputs가 튜플인 경우
outputs, outputs_kd = outputs # training일 시에 cls_embed와 dist_embed를 return 받음
base_loss = self.base_criterion(outputs, labels) # student output과 true label간의 loss
if self.distillation_type == 'none':
return base_loss
if outputs_kd is None:
raise ValueError("When knowledge distillation is enabled, the model is "
"expected to return a Tuple[Tensor, Tensor] with the output of the "
"class_token and the dist_token")
with torch.no_grad():
teacher_outputs = self.teacher_model(inputs) # 여기서 teacher model의 output을 구함
if self.distillation_type == 'soft':
T = self.tau # soft distillation에서 label smoothing을 위한 하이퍼 파라미터
distillation_loss = F.kl_div( # Kullback-Leibler divergence
F.log_softmax(outputs_kd / T, dim=1),
F.log_softmax(teacher_outputs/ T, dim=1),
reduction='sum',
log_target=True
) * (T * T)
elif self.distillation_type == 'hard':
distillation_loss = F.cross_entropy(outputs_kd, teacher_outputs.argmax(dim=1))
loss = base_loss * (1 - self.alpha) + distillation_loss * self.alpha
return loss- base(student) model의 output(cls, dist 혹은 cls 하나)을 변수에 담고 teacher model에 base model에 넣은 input image들을 그대로 넣어서 teacher output을 변수에 담는다.
- distillation없는 loss일때면 base model의 output(cls)과 labels와의 cross entropy만 계산하고 리턴한다.
- soft distillation에서는 위에서 적은 soft distillation 수식에서 오른쪽 항을 추가로 계산한다. (KL divergence)
- hard distillation에서는 hard distillation수식에서 오른쪽 항을 계산한다. (Cross entropy with teacher output argmax)
- 논문에서는 hard distillation에서 왼쪽항과 오른쪽항에 0.5를 곱해서 더했는데 실제 구현은 alpha를 통해 양쪽 항들의 가중치를 조절했다.
ENDING
이번 포스팅에서는 DeiT에 대해 알아보았다. DeiT는 distillation 학습방식과, 다양한 augmentation 그리고 ViT의 모델에 distillation token을 추가하면서 ImageNet dataset 만으로 ViT정도의 성능을 내게 되면서 앞으로의 이미지분야에서의 transformer에 대한 방향성을 제시하였다. 앞으로 계속해서 transformer에 대한 연구나 다른 분야의 모델을 이미지분야에 적용하려는 시도가 많아질 것으로 예상된다. 과연 CNN이 더 발전할 수 있을까?
Reference
'Deep Learning' 카테고리의 다른 글
| Detectron2 + weights and biases + multi gpu (17) | 2021.07.22 |
|---|---|
| [논문리뷰] Swin Transformer (1) | 2021.05.30 |
| [논문리뷰] RandAugment (7) | 2021.05.23 |
| [논문리뷰] MLP-Mixer (0) | 2021.05.18 |
| Test Time Augmentation(TTA) (0) | 2021.05.17 |
