MLP-Mixer: An all-MLP Architecture for Vision
Ilya Tolstikhin∗ , Neil Houlsby∗ , Alexander Kolesnikov∗ , Lucas Beyer∗ , Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy ∗ equal contribution Google Research, Brain Team
오늘은 2021년 5월에 나온 논문 MLP-Mixer에 대해 알아보려고 한다. 이 논문은 ViT와 마찬가지로 Google Research에서 발표하였고 핵심 아이디어는 ViT가 self attention만으로 성능을 높일 수 있다면 mlp만으로도 성능을 높일수 있지 않을까 라는것에서 시작한다. 자세히 알아보자
Model Architecture
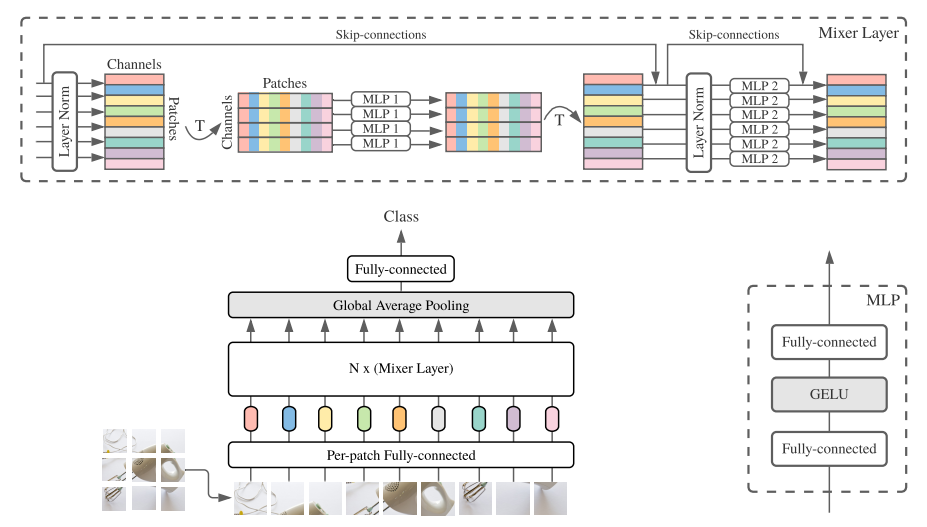
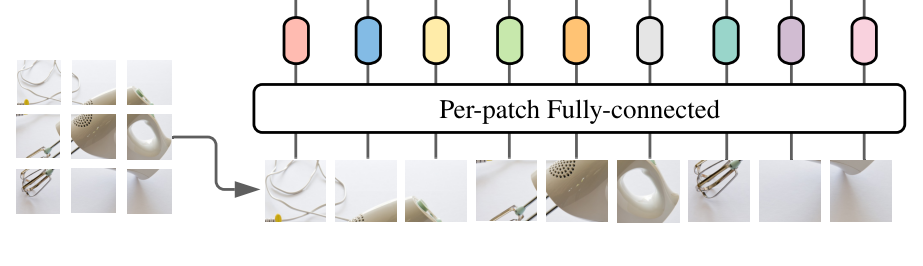
- 위 그림은 논문에 나와있는 MLP-Mixer의 model Architecture이다. 굉장히 직관적으로 이해하기 쉽게 표현하였다.
- MLP Mixer는 크게 3파트로 나눌 수 있다. 첫번째는 Patch embedding 두번째는 Mixer Block(Layer) 세번째는 head이다.
- 1. ViT와 마찬가지로 Patch embedding을 먼저 수행한다. base model은 16x16 패치사이즈로 이미지를 분할하게 되고 각 패치당 정해진 embed dimension으로 벡터화 시킨다. (ViT의 position embed를 추가하지 않은 이유는 token mixing MLP에서 입력 토큰의 순서에 의해 위치를 배운다고 가정했기 때문이다.)
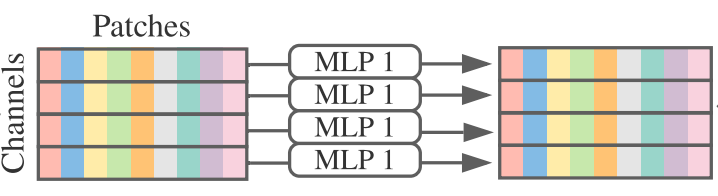
- 2. MLP Block은 위 그림에서 위쪽에 있는 block에서 직관적으로 표현하고 있다. 먼저 channel방향으로 Layer normalization을 수행한 후에 행렬을 transform시킨다.(batch x patches x channels -> batch x channels x patches ) 그 후에 MLP layer를 통해 token mixing을 하게 되고 다시 원래대로 transform 시킨다음 다시 MLP layer를 통해 이번에는 channel mixing을 하게된다. (2번을 model size에 맞게 여러번 반복 / base model은 8번 반복)
- 이때 MLP의 구조는 ViT와 동일하게 FC + GELU + FC로 이루어져 있다. (그림 오른쪽)
- 3. 각 패치당 embed dim을 가지고 있는데 이것을 global average pooling을 통해 하나로 통합시켜 최종적으로 FC-layer로 classfication한다.
MLP-Mixer is not CNN?
MLP-Mixer의 MLP Block을 보고있으면 MobileNet의 아이디어와 비슷한 느낌을 준다. 특히 token mixing은 depthwise convolution, channel mixing은 point wise(1x1) convolution 관계가 성립이 된다.
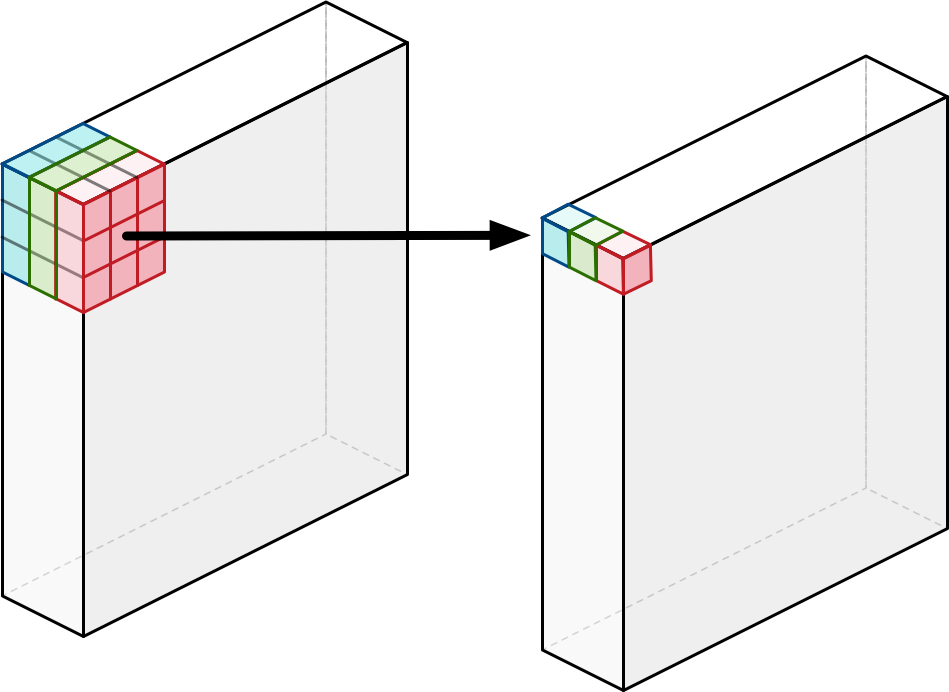
- 먼저 token mixing을 살펴보면 patch 개수에 대한 연산(base model 224x224 이미지에서의 패치개수는 14x14 = 196개)을 하게 되는데 이것을 depthwise convolution에서 오른쪽 그림에는 3x3 filter을 사용하지만 14x14 filter를 사용하게되면 token mixing(각 가로방향을 2D로 바꿨을때)에서 하는일이 depthwise convolution과 비슷하고 생각 할 수 있다.
- 다만 여기서 다른점은 token mixing은 서로 다른 채널끼리도 weight sharing을 하지만 depthwise convolution에서는 채널마다 filter가 다르기 때문에 weight sharing을 하지는 않는다는 것이다.

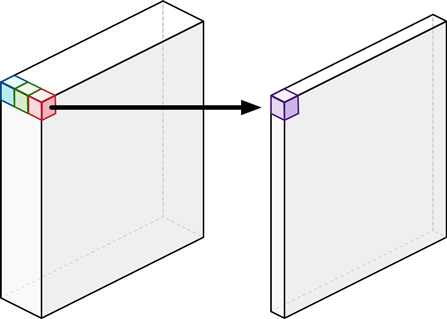
- channel mixing은 1x1 convolution이랑 거의 흡사하다고 볼 수 있다. 1x1 convolution을 하게되면 결국 채널방향으로만 연산이 수행되기 때문에 channel mixing과 하는일이 다르지 않다.
- ViT 포스팅에서도 언급했지만 Patch Embeding을 할때 Convolution을 이용하기 때문에 ViT가 CNN을 아예 사용하지 않은것은 아니라고 할 수 있다. 여기서도 마찬가지로 Convolution의 filter size와 stride를 패치사이즈로 가져가면서 convolution으로 패치를 분할하게 된다.
이러한 점들을 미뤄볼때 억측일 수 있지만 CNN을 다시 사용하는 것이 아닌가 라는 생각이 든다.
Performance
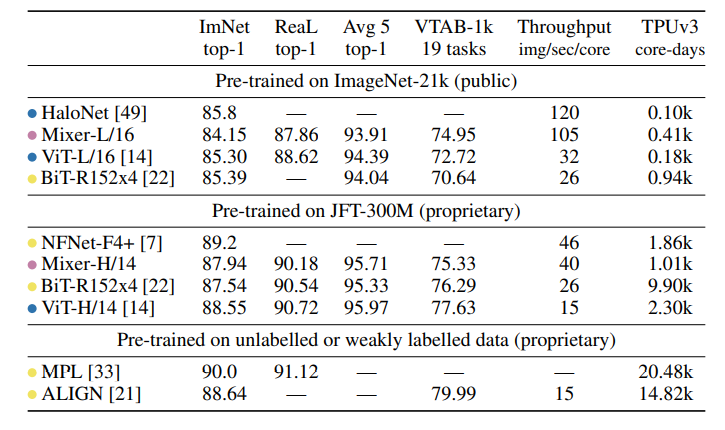
- 파란색 : attention based model / 노란색 : convolution based model
- MLP-Mixer가 SOTA의 성능까지는 보여주지 못하지만 충분히 다른 모델들과 경쟁력이 있는 것을 볼 수 있다.
- 또한 1개의 core가 1초에 처리하는 이미지가 ViT보다 훨씬 높은 것을 보면 꽤 괜찮은 것 같다.
- ImageNet-21k : 14,197,087 images / 21,841 classes
PyTorch Implementation
1. import modules
import torch
import numpy as np
import torch.nn as nn
from einops.layers.torch import Rearrange, Reduce- einops의 Rearrange를 처음 사용해 보았다. einops는 einsum과 비슷하게 matrix에 관련된 많은 연산은 직관적으로 사용할 수 있다. 연산속도가 pytorch의 함수들에 뒤지지 않는다고 한다.
- einops examples : http://einops.rocks/pytorch-examples.html
Writing better code with pytorch and einops
Learning by example: rewriting and fixing popular code fragments
einops.rocks
2. MLP(Multi Layer Perceptron)
class MLP(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super(MLP, self).__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)- ViT의 MLP와 동일하게 hidden_dim으로 갔다가 GELU activation function을 통과하고 원래 dim으로 돌아오도록 되어있다.
3. Mixer Block
class MixerBlock(nn.Module):
def __init__(self, dim, num_patch, token_dim, channel_dim, dropout=0.):
super(MixerBlock, self).__init__()
self.token_mix = nn.Sequential(
nn.LayerNorm(dim),
Rearrange('b n d -> b d n'), # (n_samples, n_patches, dim(channel)) -> (n_samples, dim(channel), n_patches)
MLP(num_patch, token_dim, dropout),
Rearrange('b d n -> b n d'),
)
self.channel_mix = nn.Sequential(
nn.LayerNorm(dim),
MLP(dim, channel_dim, dropout),
)
def forward(self, x):
x = x + self.token_mix(x)
x = x + self.channel_mix(x)
return x- MLP-Mixer의 핵심인 Mixer Block이다. Mixer Block은 token mixing과 channel mixing으로 구분할 수 있으며 mixing을 수행하기 전에 Layer Normalization을 진행하고 mixing 연산 후와 전을 skip connection해준다.
- Rearrange는 nn.Sequential 안에서 사용이 되며 위와 같은 문자열로 차원을 표현해서 torch.permute() or torch.transpose() 의 역할을 하게 된다.
4. MLP-Mixer
class MLPMixer(nn.Module):
def __init__(self, in_channels, dim, num_classes, patch_size, image_size, depth, token_dim, channel_dim):
super(MLPMixer, self).__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size'
self.num_patch = (image_size // patch_size) ** 2
self.patch_embedding = nn.Sequential(
nn.Conv2d(in_channels, dim, patch_size, patch_size),
Rearrange('b c h w -> b (h w) c'), # h,w = num_patch ** 0.5
)
self.mixer_blocks = nn.ModuleList([])
for _ in range(depth):
self.mixer_blocks.append(
MixerBlock(dim, self.num_patch, token_dim, channel_dim)
)
self.layer_norm = nn.LayerNorm(dim)
self.mlp_head = nn.Linear(dim, num_classes)
def forward(self, x):
x = self.patch_embedding(x) # (2, 196, 512)
for mixer_block in self.mixer_blocks:
x = mixer_block(x) # (2, 196, 512)
x = self.layer_norm(x)
x = x.mean(dim=1) # global average pooling (2, 512) / sequential을 사용했다면 Reduce('b n d -> b d', 'mean') 도 가능
x = self.mlp_head(x) # (2, 1000)
return x- 전체 구조를 구축하는 클래스 MLPMixer
- 먼저 patch embedding을 하는데 convolution을 통해 패치를 분할하고 벡터로 만들기 위해 Rearrange를 사용한다.
- 위에서 사용한 Rearrange : (batch, channel, height, width) -> (batch, height x width, channel)
- 그 후에 n번의 mixer block 연산 + layer Norm + 패치 통합(x.mean(dim=1)) + clasifier를 통해 output을 내게 된다.
5. Result
if __name__ == "__main__":
from torchsummary import summary
import pdb
# --------- base_model_param ---------
in_channels = 3
hidden_size = 512
num_classes = 1000
patch_size = 16
resolution = 224
number_of_layers = 8
token_dim = 256
channel_dim = 2048
# ------------------------------------
model = MLPMixer(
in_channels=in_channels,
dim=hidden_size,
num_classes=num_classes,
patch_size=patch_size,
image_size=resolution,
depth=number_of_layers,
token_dim=token_dim,
channel_dim=channel_dim
)
img = torch.rand(2, 3, 224, 224)
output = model(img)
print(output.shape)
# summary(model, input_size=(3, 224, 224), device='cpu')
parameters = filter(lambda p: p.requires_grad, model.parameters())
parameters = sum([np.prod(p.size()) for p in parameters]) / 1_000_000 # 18.528 million
print('Trainable Parameters: %.3fM' % parameters)Output
torch,Size([2, 1000])
Trainable Parameters: 18.528M
ENDING
오늘은 굉장히 최근에 나온 논문 MLP-Mixer에 대해 알아보았다. 모델이 굉장히 직관적이고 간단해서 구현코드가 일반적인 CNN코드보다 훨씬 간결하다. 이 논문을 보면서 FC layer 와 Convolution과의 관계를 다시 한번 생각해 보게 되었고 구글에 감사함을 느낀다.
Keep going
Reference
- Paper - https://arxiv.org/abs/2105.01601?utm_source=aidigest&utm_medium=email&utm_campaign=155
- Review1 - https://www.youtube.com/watch?v=7K4Z8RqjWIk&t=1304s
- Review2 - https://www.youtube.com/watch?v=KQmZlxdnnuY&t=1189s
- Code - https://github.com/tjems6498/Image_Classification/blob/master/MLP_mixer/mlp-mixer.py
'Deep Learning' 카테고리의 다른 글
| [논문리뷰] DeiT (Data-efficient image Transformers) (0) | 2021.05.25 |
|---|---|
| [논문리뷰] RandAugment (7) | 2021.05.23 |
| Test Time Augmentation(TTA) (0) | 2021.05.17 |
| [논문리뷰] Vision Transformer(ViT) (3) | 2021.05.15 |
| [논문리뷰] EfficientNet (0) | 2021.02.21 |
