이번 포스팅에는 2022년 1월 FAIR에서 발표한 'A ConvNet for the 2020s' 라는 논문을 리뷰하려고 한다. 해당 논문은 2020년에 ViT(Vision Transformer)가 발표된 이후 Vision task에서 Transformer에 연구가 집중되고 있지만 CNN에 Transformer 구조 및 최신 기법들을 적용한 ConvNeXt라는 모델을 제안하고 있으며 높은 성능을 통해 CNN이 여전히 강하다는것을 주장하는 논문이다.

보라색은 CNN, 주황색은 Transformer 기반 Network이며 버블의 크기는 모델의 FLOPs를 의미한다. 저자들이 제안한 ConvNeXt가 ImageNet-1K, 22K 데이터셋 모두 현재 SOTA인 Swin Transformer의 accuracy를 조금 넘어서는듯한 그래프를 보이고있다. 어떤 방법으로 CNN Architecture의 성능을 높였는지 자세히 살펴보자.
1. Introduction
CNN 모델들은 2012년에 발표된 AlexNet을 기점으로 VGGNet, ResNe(X)t, DenseNet, MobileNet, EfficientNet, RegNet 등 수많은 모델들이 발표되면서 점진적으로 발전되어 왔다. CNN은 Sliding Window를 활용하며 그 영역안의 weight들은 서로 공유된다는 전략을 가지고 있으며 이러한 Inductive bias를 통해 CNN은 Image Recognition 분야에서 backbone network 로써 오랫동안 자리를 잡아왔다.
점진적으로 발전되어 왔던 Vision task의 CNN과는 다르게 NLP분야에서는 RNN에서 Transfomer로 모델이 급격하게 변화하였고 2020년에 ViT논문이 발표면서 이제는 Transformer가 Vision task 까지 넘어오게 되었다. Input 이미지를 Patch단위로 나누어 마치 NLP Transfomer의 input이되는 단어처럼 표현하게 된다. ViT는 큰 모델과 데이터셋에 대한 좋은 scaling으로 ResNet의 성능을 넘어서게 되었다. 하지만 ViT는 모든 패치간의 attention을 구하기 때문에 이미지 사이즈가 커질수록 quadratic complexity에 대한 문제가 있었다.
2021년에 Swin Transformer(Shifted Window Transformer) 논문이 발표되면서 이 문제를 어느정도 해결하였다. Swin Transformer는 레이어 block이 지날수록 patch들을 merge시켜나가는 Hierarchical 구조를 가지고 있으며 모든 patch간의 attention을 구하지 않고 patch를 감싸는 window를 지정해 이 안에있는 patch들간의 attention만 계산하게 된다. 이러한 방법으로 Image classification은 물론 Object Detection, Instance Segmentation까지 SOTA를 달성하였다.
하지만 Swin Transformer는 구현하는데 CNN보다 많은 비용이 들며 cyclic shifting을 통해 속도를 최적화 할 수 있지만 설계가 정교해야 한다는 단점이 있다. 또한 Swin Transformer가 적용한 Window는 결국 CNN의 Sliding Window를 다시 가져온 것이라고 볼 수 있다.
때문에 이 논문의 목표는 ViT 이전과 이후의 모델들의 gap을 줄이고 pure ConvNet이 달성할 수 있는 한계를 테스트 하는 것이고 ResNet50을 base로 hierarchical Transformer를 CNN으로 modernize하여 점차 성능을 높인 ConvNeXt라는 모델을 제안한다.
2. Modernizing a ConvNet: a Roadmap
논문에서는 FLOPs(4.5x10^9)가 서로 비슷한 ResNet-50 / Swin-T(tiny)를 비교하면서 진행된다.

ConvNeXt는 현대화된 training technique을 적용했으며 다음과 같은 순서로 모델을 Design하였다.
- macro design
- ResNeXt
- inverted bottleneck
- large kernel size
- various layer-wise micro designs.
2.1 Training Techniques
저자들은 Base model(ResNet-50/200)에 다음과 같은 modern training techniques를 적용하였다.
- original 90 epochs -> extended to 300 epochs
- AdamW optimizer
- Data Augmentation : Mixup, Cutmix, RandAugment, Random Erasing, regularization schemes including Stochastic
Depth, Label Smoothing
위와 같은 기법들을 적용했을때 ResNet-50의 성능인 76.1%에서 78.8%로 올렸으며 이 값이 위 그래프의 첫부분에 해당된다.
2.2 Macro Design

위 그림과 같이 Swin-Transformer는 Input을 Patch단위로 나누었으며 Hierarchical 구조를 4개의 Block단위로 분리하였다. 이 두가지를 아래와 같이 적용시켰다.
Changing stage compute ratio.
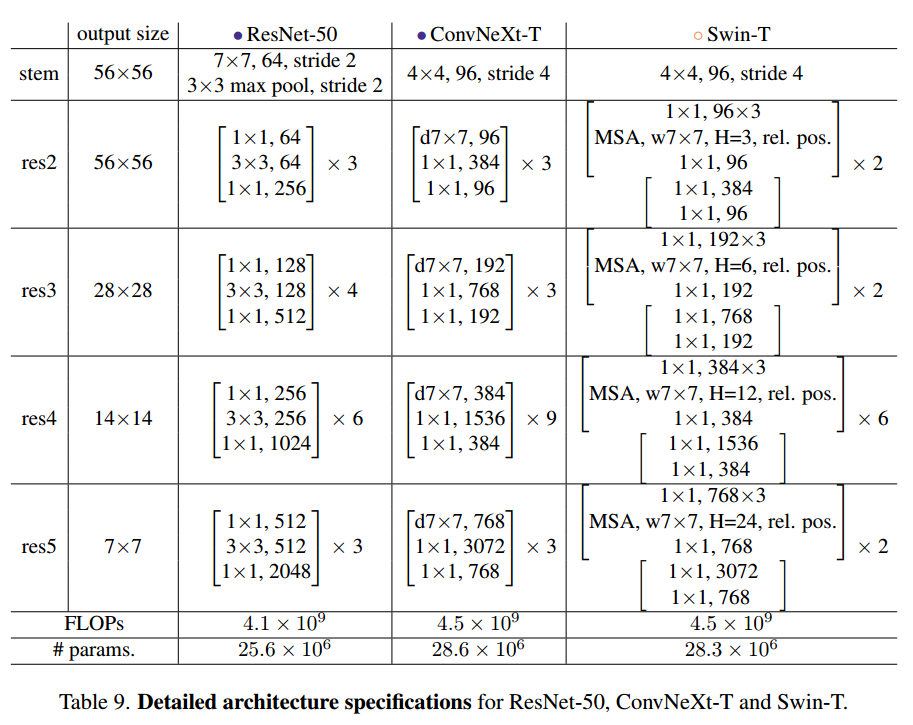
Swin-T에서는 1:1:3:1 비율로 Block이 실행되며 Large 모델은 1:1:9:1로 되어있다. 때문에 기존 ResNet-50에서 사용하던 (3,4,6,3)의 residual block 개수를 (3,3,9,3)으로 변경시켰고 정확도가 78.8% -> 79.4%로 높아졌고 block개수가 많아진 만큼 FLOPs도 4.1G에서 4.5G로 증가하였다.
Changing stem to “Patchify”.
먼저 기존 모델들의 Stem부분을 살펴보자면 ResNet은 7x7 filter, stride 2, max pool를 통해 input image를 4배 downsampling하며, Vision Transformer는 14x14 혹은 16x16으로 이미지를 patch단위로 나누며 Swin Transformer는 더 작은 단위인 4x4 path단위로 나눈다. 여기서 저자들은 4x4 filter size에 stride 4를 주어 convolution을 수행하였고 이는 Non-overlapping convolution이 Swin-T의 stem이랑 같은 일을 하는것이라는 것을 알 수 있다. patchify stem을 적용한 결과 정확도는 79.4%에서 79.5%로 미세하게 올랐으며 FLOPs는 0.1G 감소하였다.
2.3. ResNeXt-ify
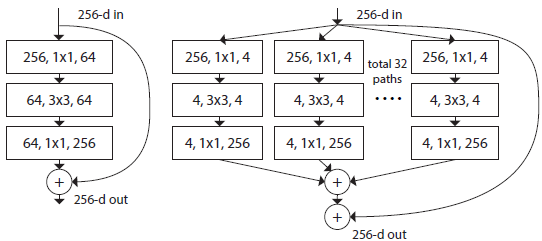
저자들은 RssNeXt의 아이디어를 통해 FLOPs와 Accuracy 간의 더 좋은 Trade-off를 얻으려고 했다. 위 그림의 왼쪽은 ResNet, 오른쪽은 ResNeXt의 구조이며 ResNeXt의 특징은 input channel을 32개의 patch로 나누어 각자 연산을 한 후 다시 concatenate시키는 grouped convolution을 한다는 것이다.
이 아이디어를 더욱 확장해서 group 개수를 channel수만큼 만들어 MobileNet에서 사용했던 Depthwise convolution을 적용하여 FLOPs를 대폭 줄이게 된다. 하지만 이렇게 하면 성능은 떨어지기 때문에 추가적으로 Swin-T와 채널을 맞추기 위해 width를 64에서 96으로 증가시켜 결과적으로 80.5%(1% up) Accuracy, 5.3G FLOPs(0.9G up)를 얻었다.
2.4. Inverted Bottleneck
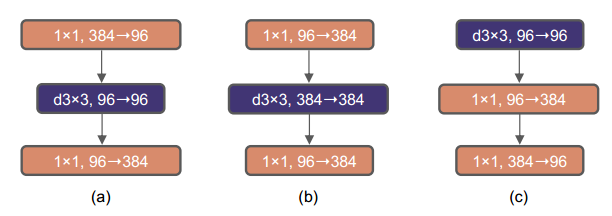
기존 ResNet은 그림(a)와 같이 1x1 conv로 채널을 줄인 후 3x3 conv를 진행하고 다시 1x1으로 채널을 키우는 Bottleneck 구조를 가지고 있다. Mobilenet V2에서는 FLOPs를 줄이기 위해 그림(b)와 같은 Inverted Bottleneck을 사용하였다.
논문에서 저자들은 Transformer block에서도 inverted bottleneck이 이미 사용되고 있었다고 한다. Transformer의 MLP block에서는 채널을 4배 늘린 후 다시 원래로 되돌리는데 1x1 convolution이 결국에는 fc layer와 같은 일을 하기 때문이라고 한다. 그래서 ConvNeXt에도 inverted bottleneck을 적용하였는데 downsampling residual block에 의해 많은 FLOPs가 감소되었으며 80.6% Accuracy (0.1% up) 4.6G FLOPs(0.7 down)의 성능을 보였다.
2.5. Large Kernel Sizes
이전에는 large kernel을 사용했었지만 VGGNet에서 3x3 conv layer가 연산량이 적어 많은 레이어를 쌓아 성능을 높인 이후로 대부분의 모델에서 3x3 convolution을 기본으로 사용하게 되었다. 하지만 Swin Transformer에서는 window size를 7x7(49개의 patch)로 가져갔다. 이에 저자들은 기존 ResNe(X)t 모델의 3x3 kernel 대신 larget kernel-size conv에 대해 실험하였다.
Moving up depthwise conv layer.
그전에 위에서 Inverted Bottleneck의 그림(b)를 적용했다고 했다. 그런데 이 구조를 Swin-T에 비교해보자면 MLP block 안에서 MSA(Multi head Self-Attention)을 수행하는 것이 된다. 그렇기 때문에 저자들은 inverted block을 Swin-T의 구조를 적용하여 그림(c)처럼 MSA를 먼저 수행하고 MLP를 수행하는 구조로 좀 더 자연스럽게 변환하였다. 이에 따라 연산량은 감소하였지만 정확도도 조금 낮아졌다. [79.9% Accuracy (0.7% down) 4.1G FLOPs(0.5 down)]
Increasing the kernel size.
저자들은 3,5,7,9,11 kernel size 모두 실험을 통해 7x7 kernel size가 saturation 되었다고 하며 FLOPs는 거의 유지된 상태로 정확도가 79.9%(3x3) 에서 80.6%(7x7)으로 향상되었다.
2.6. Micro Design
이 섹션은 activation function, normalizeation layer와 같은 micro scale에 대한 변경사항에 대해 다룬다.
Replacing ReLU with GELU
NLP와 vision architecture 사이에는 activation function에 차이가 있다. 수많은 activation function이 개발되었지만 여전히 ReLU(Rectified Linear Unit)가 단순하고 효율적이기 때문에 ConvNet에서 여전히 널리 쓰이고 있다. original Transformer에서도 ReLU를 사용했지만 이후로 NLP에서는 ReLU의 smoother vaiant 버전인 GELU(Gaussian Error Linear Unit)가 BERT, GPT-2, ViT등 최근 연구에서 많이 사용되고 있다. 정확도와 FLOPs는 변하지 않았지만 저자들은 모든 activation function을 GELU로 사용하였다.
Fewer activation functions
일반적인 ConvNet은 conv -> normalization -> activation 이 공식화 되어있다. 하지만 Transformer는 ResNet block과 다르게 적은 activation function을 사용하고 있다. MSA 부분에는 activation이 없고 MLP block에 단 한개의 activation function만 포함한다. 이러한 Transformer의 전략을 가져오기 위해 ConvNeXt에서는 두개의 1x1 convolution(위의 그림 c) 사이에 하나의 GELU만을 사용하였고 여기서 정확도를 81.3%(0.7% up) 까지 올리게 된다.
Fewer normalization layers.
Transformer에서는 normalization layer도 MSA, MLP block 앞에서만 수행한다. ConvNeXt에서는 한개의 BatchNorm을 inverted bottleneck의 첫번째 1x1 conv layer 앞쪽에 적용시켜 81.4%(0.1% up)의 Accuracy를 보였다. 여기까지 진행하였을때 벌써 Swin-T의 81.3%를 넘어서게 된다.
Substituting BN with LN.
Batch Normalization은 잘 수렴되며 Overfitting을 방지하는 차원에서 ConvNet에서 일반적으로 사용 되어왔지만 batch size에 따른 성능 변화의 편차가 심하다는 등 모델의 성능에 좋지않은 영향을 줄 수 있는 intricacies가 있다. 반면에 Transformer에서는 Layer Normalization을 통해 높은 성능을 내고있다.
LN을 바로 ResNet에 적용시키면 오히려 성능이 떨어지지만 지금까지 많은 mordern technique을 적용한 ConvNeXt에서는 약간의 성능 향상(81.5%(0.1% up))을 이끌어 내었다.
Separate downsampling layers.
기존 ResNet은 각 block이 끝난 뒤 높은 channel로 feature extraction을 하기 위해 다음 block의 첫번째 layer를 3x3 conv, stride 2를 사용해 width와 height를 절반으로 줄이게 된다. (즉 block과 block 사이에 추가적인 layer가 있는 것이 아니라 block의 start layer의 값을 조정하여 진행)
하지만 Swin Transformer에서는 downsampling layer(patch merging)가 따로 존재하기 때문에 ConvNeXt에서도 downsampling을 위한 layer를 추가하였다. 이때 2x2 conv, stride 2를 사용하였다. 하지만 단순히 레이어만 추가했을 때 학습이 발산되어 Normalization layer을 추가하여 학습을 안정화 시켰고 결국 82.0% 까지 정확도를 끌어올렸다.(FLOPs 0.3G 증가)

3. Result
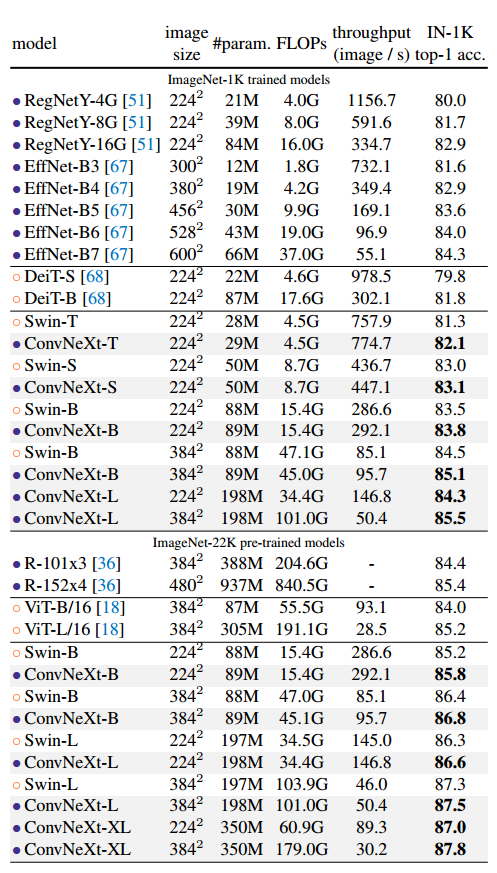
Swin Transformer와 직접적으로 비교를 하면서 같은 조건하에 조금씩 ConvNeXt가 더 성능이 좋은것을 볼 수 있다. 또한 ViT와 같이 Inductive bias가 적은 모델은 ImageNet-22K와 데이터를 많이 넣었을때 성능이 더 좋다는 것이 일반적이다. 하지만 잘 디자인 된 ConvNet은 큰 데이터셋에 대한 성능이 절대로 뒤지지않고 오히려 넘어선 다는것을 위 표에서 보여주고 있다.
여기에 더해 저자들은 단순히 ConvNeXt가 FLOPs 대비 성능만 좋은것이 아니라 실용적으로도 efficiency하다는 것을 증명하였다. 일반적으로 같은 FLOPs를 가진 두 모델이 있을때 depthwise convolution을 적용한 모델이 더 느리고 메모리를 더 많이 사용한다는 것은 알려진 사실이다. 하지만 ConvNeXt는 depthwise conv layer를 inverted bottleneck의 맨 위로 올리면서 채널수를 1/4로 만들어 연산량을 줄였기 때문에 다른 모델에 비해 practical한 부분이 전혀 뒤쳐지지 않는다는 것을 결과로 보여주었다.
저자들은 이 efficieny가 Transformer의 self-attention과 관련된 것이 아니라 오직 Convolution의 inductive bias에서 오는것이라는 것을 강조한다.
4. Conclusions
ConvNeXt가 pure ConvNet으로 이루어 졌으며 Swin Transformer의 ImageNet-1k에서의 성능을 충분히 넘어 설 수 있다는 것을 보였다. 하지만 여기에 적용된 technique들은 새롭게 만들어진 것이 아니라 지난 몇년동안 따로 나온것들을 종합하여 이뤄낸 성과라고 말한다.
또한 ConvNeXt는 Swin Transformer의 shifted window attention, relative position biases와 같은 specialized modules을 요구하지 않으면서 FLOPs, #params., throughput, and memory use와 같은 지표가 거의 동일하다는 것을 말하며 Convolution에 대한 중요성을 일깨우고 있다.
Pytorch Implementation
Basic Block
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
import pytorch_model_summary
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super(Block, self).__init__()
# Depthwise Convolution(Swin-T의 MSA)
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, stride=1, padding=3, groups=dim)
self.norm = nn.LayerNorm(dim, eps=1e-6)
# Pointwise Convolution(Swin-T의 MLP)
self.pwconv1 = nn.Linear(dim, dim*4)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(dim*4, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
# stochastic depth
self.drop_path = DropPath(drop_path) if drop_path > 0 else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C) LN을 하기 위해 채널을 맨 뒤로 보냄
x = self.norm(x)
x = self.pwconv1(x) # (N, H, W, C*4)
x = self.act(x)
x = self.pwconv2(x) # (N, H, W, C)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
return input + self.drop_path(x) # skip connection- ConvNeXt의 inverted bottleneck 부분으로 Depthwise convolution과 두개의 Fully connected layer(pointwise)로 이루어져 있다.
- forward에서 torch.nn에 내장된 Layer Normalization을 사용하기위해 permute으로 channel 차원을 맨 뒤로 보내게 되고 자연스럽게 Linear layer 두개를 통과시킨 후 다시 permute으로 원래차원으로 되돌려 skip connection을 진행한다.
Implement Layer Normalization
class LayerNorm(nn.Module):
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super(LayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ['channels_last', 'channels_first']:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first": # 직접 구현
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x- Pytorch에서는 convolution layer에서 (batch, channel, width, height)와 같은 차원을 받아들이기 때문에 차원을 변환하지 않고서는 맨 끝 차원을 channel로 해야하는 Layer Norm을 사용할 수 없다.
- torch.nn의 LayerNorm과 torch.nn.functional의 layer_norm함수가 있음에도 불구하고 직접 class를 구현한 이유는 downsampling 과정에서 추가되는 LayerNormalization만 사용하기 위해 차원을 굳이 변경할 필요가 없기 때문에 (batch, channel, width, height)의 차원에서 바로 LayerNormalization을 수행하기 위함이다.
- 이러한 이유와는 상반되게 Basic Block에서 번거롭게 차원을 변경해준 이유는 linear layer를 pointwise convolution(1x1 convolution)으로 활용하기 위해서는 어차피 channel을 맨 끝 차원으로 보내야 하기 때문으로 보인다.
ConvNext
class ConvNeXt(nn.Module):
def __init__(self, in_channels=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],
drop_path_rate=0., layer_scale_init_value=1e-6, head_init_scale=1.):
super(ConvNeXt, self).__init__()
self.downsample_layers = nn.ModuleList()
stem = nn.Sequential(
nn.Conv2d(in_channels, dims[0], kernel_size=4, stride=4), # like patch embedding
LayerNorm(dims[0], eps=1e-6,data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"), # 발산을 막기 위한 normalize
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList()
dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stage가 깊어질수록 stochastic depth가 적용될 확률이 높아짐
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur+j], layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i] # next stage
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
# initialization
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
for i in range(4):
x = self.downsample_layers[i](x) # stem, downsample_layer1, downsample_layer2, downsample_layer3
x = self.stages[i](x) # stage1, stage2, stage3, stage4
x = self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
return self.head(x)- stem부분을 보면 kernel_size=4, stride=4를 활용했다. 이는 위에서 언급한 것 처럼 Swin Transformer에서 input을 patch로 분할한 것과 동일한 역할을 한다.
- Layer Normalization은 stem layer 이후에 한번, 각 downsample layer에서 conv layer 앞에서 한번, 마지막 head linear layer 앞에서 한번 수행된다.
Print ConvNeXt-T Architecture
def convnext_tiny(**kwargs):
model = ConvNeXt(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], **kwargs)
return model
if __name__ == '__main__':
model = convnext_tiny()
print(pytorch_model_summary.summary(model, torch.zeros(2, 3, 224, 224), show_input=True))output:
------------------------------------------------------------------------
Layer (type) Input Shape Param # Tr. Param #
========================================================================
Conv2d-1 [2, 3, 224, 224] 4,704 4,704
LayerNorm-2 [2, 96, 56, 56] 192 192
Block-3 [2, 96, 56, 56] 79,296 79,296
Block-4 [2, 96, 56, 56] 79,296 79,296
Block-5 [2, 96, 56, 56] 79,296 79,296
LayerNorm-6 [2, 96, 56, 56] 192 192
Conv2d-7 [2, 96, 56, 56] 73,920 73,920
Block-8 [2, 192, 28, 28] 306,048 306,048
Block-9 [2, 192, 28, 28] 306,048 306,048
Block-10 [2, 192, 28, 28] 306,048 306,048
LayerNorm-11 [2, 192, 28, 28] 384 384
Conv2d-12 [2, 192, 28, 28] 295,296 295,296
Block-13 [2, 384, 14, 14] 1,201,920 1,201,920
Block-14 [2, 384, 14, 14] 1,201,920 1,201,920
Block-15 [2, 384, 14, 14] 1,201,920 1,201,920
Block-16 [2, 384, 14, 14] 1,201,920 1,201,920
Block-17 [2, 384, 14, 14] 1,201,920 1,201,920
Block-18 [2, 384, 14, 14] 1,201,920 1,201,920
Block-19 [2, 384, 14, 14] 1,201,920 1,201,920
Block-20 [2, 384, 14, 14] 1,201,920 1,201,920
Block-21 [2, 384, 14, 14] 1,201,920 1,201,920
LayerNorm-22 [2, 384, 14, 14] 768 768
Conv2d-23 [2, 384, 14, 14] 1,180,416 1,180,416
Block-24 [2, 768, 7, 7] 4,763,136 4,763,136
Block-25 [2, 768, 7, 7] 4,763,136 4,763,136
Block-26 [2, 768, 7, 7] 4,763,136 4,763,136
LayerNorm-27 [2, 768] 1,536 1,536
Linear-28 [2, 768] 769,000 769,000
========================================================================
Total params: 28,589,128
Trainable params: 28,589,128
Non-trainable params: 0
------------------------------------------------------------------------
Process finished with exit code 0END
Vision 분야에서 CNN으로 SOTA 성능을 달성한 논문을 오랜만에 보는 것 같다. 요즘 많은 사람들이 CNN의 성능에 한계를 느끼고 갑자기 혜성처럼 등장한 Transformer가 기존의 CNN을 능가하는 수준의 결과가 나와서 대부분 Transformer를 기반으로한 연구가 진행되는 것 같다. 하지만 ConvNeXt 저자들이 언급한 것 처럼 Vision에서 사용되는 Transformer의 아이디어는 CNN으로부터 출발한 것이기 때문에 잘 디자인된 ConvNet이 잊혀지진 않을 것이라고 생각한다.
ConvNeXt와 Swin Transformer는 서로의 모델을 참조한 것이기 때문에 어쩌면 나중에 큰 격차로 SOTA를 달성하게 될 모델은 CNN도 Transformer도 아닌 새로운 Architecture가 되지 않을까?
keep going
Reference
Paper - https://arxiv.org/abs/2201.03545
Code - https://github.com/facebookresearch/ConvNeXt
Review1 - https://youtu.be/OpfxPj2AIo4
Review2 - https://youtu.be/Mw7IhO2uBGc
'Deep Learning' 카테고리의 다른 글
| [논문리뷰] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers (7) | 2022.05.22 |
|---|---|
| Focal Loss (4) | 2022.01.02 |
| [블로그 리뷰] Self-supervised learning: The dark matter of intelligence (0) | 2021.12.16 |
| [논문리뷰] Masked Autoencoders Are Scalable Vision Learners (0) | 2021.12.01 |
| Inference with OpenVINO (0) | 2021.11.17 |
