YOLO v3: An Incremental Improvement - Joseph Redmon, Ali Farhadi (8 Apr 2018)
1. Introduction
저자 Joseph Redmon은 이 논문은 단지 Tech Report라고 하였다. YOLO v3는 기존 YOLO v2보다 Better, Not Faster, Stronger(?) 를 주장하며 여러가지 시도를 하였다.
2. The Deal
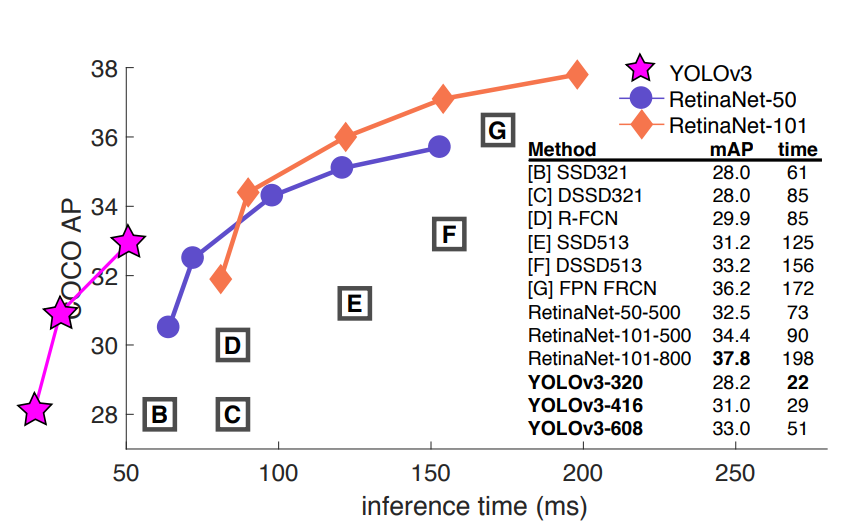
위 사진을 보면 알 수 있듯이 당시 SOTA 였던 RetinaNet을 비교하며 그래프 형식을 무시하면서 YOLO v3의 속도를 과시하고 있다.
2.1 Bounding Box Prediction
YOLO v3 에서는 YOLO v2에서 처음 사용하였던 Anchor box를 그대로 가져와서 사용을 하게된다.

tx, ty, tw, th가 예측값이 되고 그 예측값에 수식을 더해 최종적으로 bx, by, bw, bh의 정보를 가지고 후처리하여 화면에 뿌려주게 된다. (loss값은 sigma(tx), sigma(ty), tw, th와 정답을 비교해서 구함)
Objectness score(confidence)에 Logistic Regression을 사용한다.
2.2 Class Prediction
저자는 평소 사용해왔던 softmax 방법이 좋은성능을 내는데에 불필요하다고 느껴서 단순하게 multilabel classification에 logistic classifiers를 사용했다. training과정에서 binary cross-entropy loss를 사용함으로서 Hierarchical(계층적인) 데이터가 있는 도메인에 적용할 수 있도록 도와준다고 한다. softmax는 단 하나의 클래스만 선택하기 때문에 이런 부분에 있어서 multilabel의 logistic이 이점을 가진다.
2.3 Predictions Across Scales
YOLO v3에서 바뀐점은 v2처럼 K-mean clustering방식으로 Anchor box를 뽑지만 5개가 아닌 9개를 3개씩 다른 scale을 가지는 box를 뽑아서 3곳의 detection feature_map에서 3개씩 사용을 하게 된다.
- 사용된 9개 box scale(COCO) : (10×13),(16×30),(33×23),(30×61),(62×45),(59× 119),(116 × 90),(156 × 198),(373 × 326)
그러므로 Detection을 하는 Feature_map 3곳의 입력값은 N x N x [3 * (4 + 1 + 80)]이 된다.
N : 각 scale의 size (13, 26, 52)
3 : number of Anchor boxes
4 : box offset (x, y, w, h)
1 : objectness prediction
80 : COCO dataset classes
2.4 Feature Extractor
Joseph Redmon은 backbone network로 YOLO v1에서는 GoogLeNet, YOLO v2에서는 Darknet19, 그리고 이번에는 Darknet53을 사용하였다. Darknet53은 아래 그림과 같이 구성되어 있으며 눈여겨 볼 것은 ResNet의 skip connection을 사용하였다는 점이다. 또한 1x1 convolution을 통해 연산량을 줄였으며 결과적으로 다른 classification network보다 조금더 좋은 성능을 내게된다.

YOLO v3 모델에서는 위의 Darknet53 backbone network에 더해 수십개의 layer를 더 추가 하였는데 그 모습은 아래와 같다.
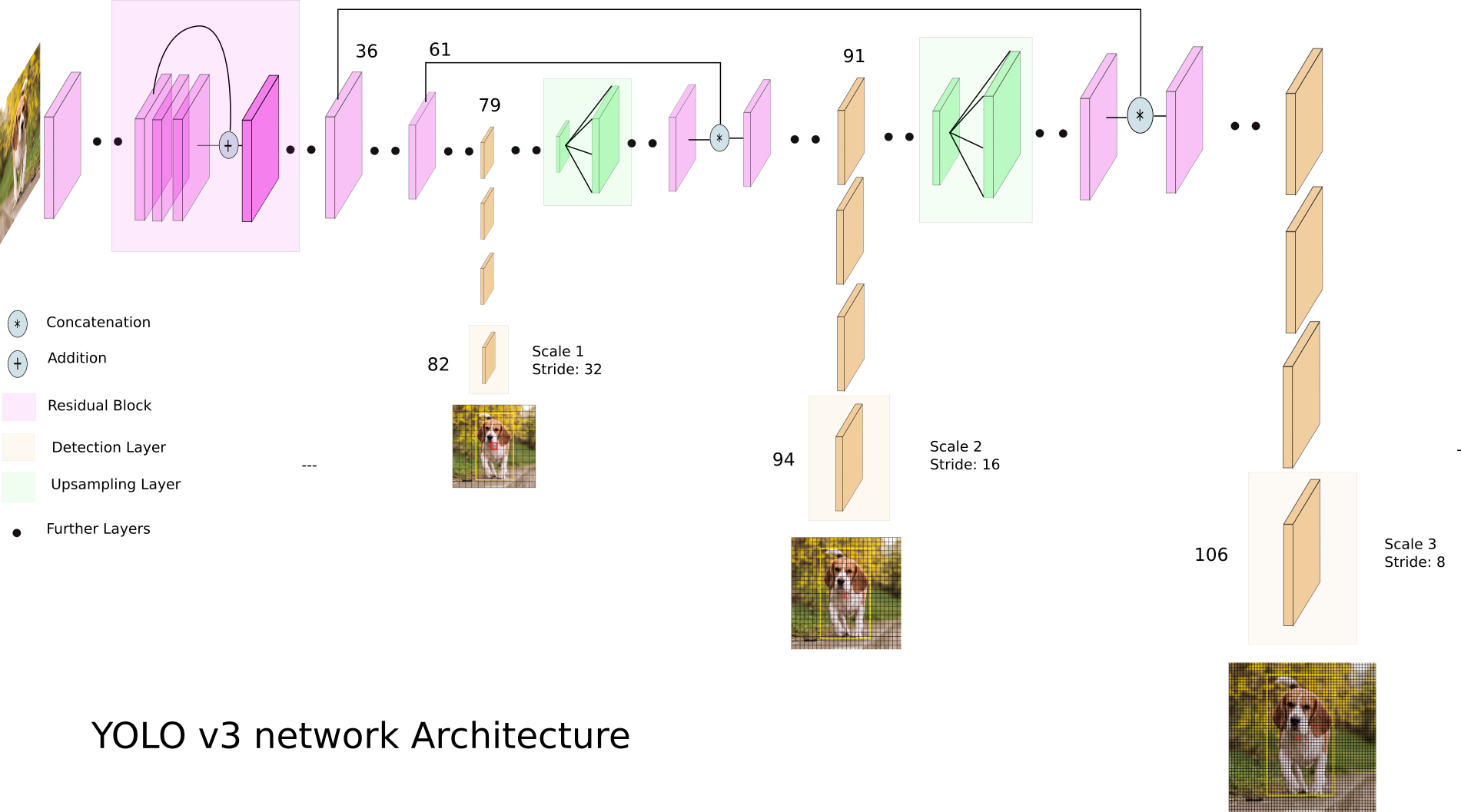
위에서 잠깐 언급하였지만 YOLO v3에서는 세곳에서 Detection을 수행한다. 이 아이디어는 SSD의 multi box detector와 RetinaNet의 Feature pyramid 방식과 유사한데 작은 feature map에서는 비교적으로 큰 물제를 잘 찾고 큰 feature map에서는 작은 물체를 잘 찾는다는 것을 활용하여 사이즈가 다른 여러곳에서 Detection을 하여 종합하여 처리하는 방식이다.
Yolo v3은 feature pyramid에 좀더 가까운데 먼저 feature_map을 13 x 13까지 줄인 후에 upscale과 concatenate로 26 x 26 마지막으로 52 x 52 사이즈까지 늘려서 사용을 하고있다.
추가로 3개의 Feature_map에서의 예측값을 각 박스의 예측값으로 뽑아내기 위해 아래와 같은 방식으로 재표현하여 사용한다.
- (batch, 255, 13, 13) -> (batch, 507, 85)
- (batch, 255, 26, 26) -> (batch, 2028, 85)
- (batch, 255, 52, 52) -> (batch, 8112, 85)
- 총 10647개의 bounding box
2.5 Training
이번에도 역시 SSD에서 쓰인 Hard Negative Mining 기법을 사용하지 않고 Confidence를 통해 물체가 없는 곳의 박스는 바로 날려버릴 수 있도록 하였고 기본적인 data augmentation, batch normalization등 standard한 기법들은 다 사용을 하였다.
3. How We Do
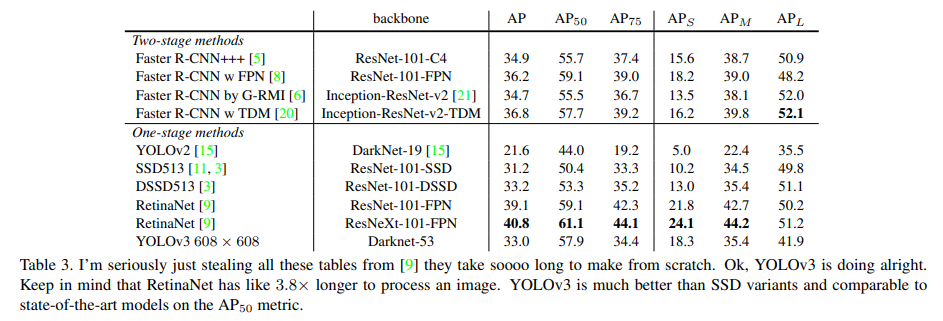
YOLO v3의 AP50 에서의 성능은 SOTA에 견줄만 할 정도로 좋아졌고 특히 YOLO의 고질적인 문제였던 작은 물체를 잘 찾지 못하던 것을 좀 더 잘 찾게 되었다. 하지만 중간~큰 물체에 대한 성능은 조금 좋지 않았는데 좀더 연구가 필요하다고 한다.
4. What This All Means
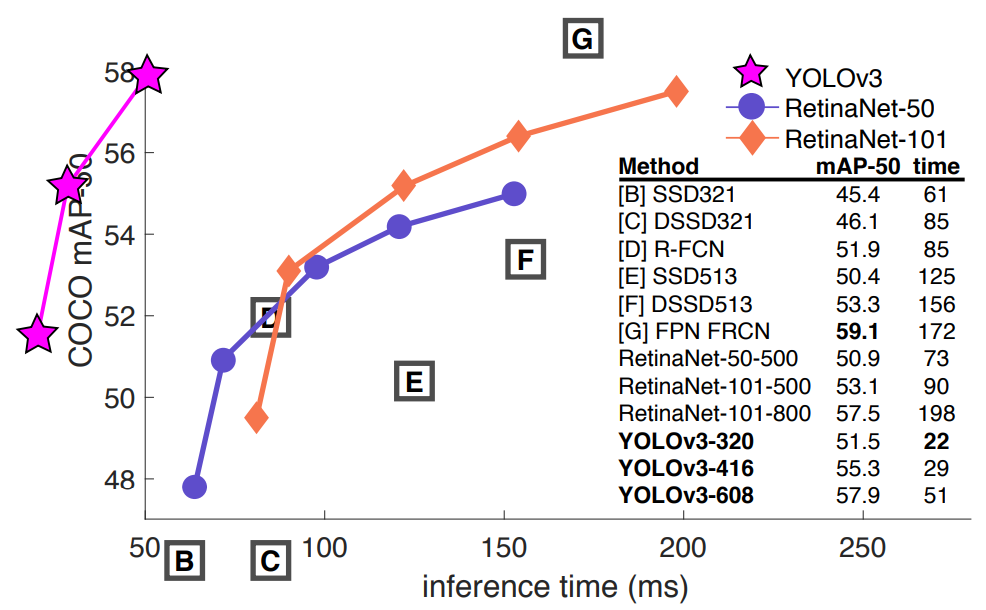
Joseph Redmon은 COCO dataset의 성능평가 방법에 대해 굉장히 불만이 많았다. 그 이유는 mAP를 계산할때 IOU 0.5에서 0.95까지 0.05씩 늘려가면서 그것들의 평균을 재기 때문이다. Russakovsky의 report에 따르면 사람은 IOU가 0.3인것과 0.5인것의 차이를 잘 느끼지 못한다는 연구결과가 있다고 한다.
그럼에도 불구하고 굳이 이렇게 0.05씩 차이를 둬가면서 mAP에 대해 또다시 평균을 내는 것에 대해 불만을 토했다. 그리고 마지막 말로 자신의 모델이 military에 사용되어 사람을 죽이는 데에 사용이 된다는 것을 알고 Computer Vision 업계를 떠난다고 하였고 실제로 사라지게 된다..
ENDING
YOLO v2와 v3의 차이가 크지 않기 때문에 바로 v3으로 넘어와서 논문 구현코드를 샅샅히 파헤쳤다. 논문 내용과는 별개로 cfg 파일을 parsing하는 방법, 우분투 shell을 통하여 데이터를 다운받는 방법 등을 새롭게 알게 되었다. 계속해서 코드를 보다보니 이제 차원을 다루는 것에 대해 조금 익숙해진 것 같고 확실히 논문 및 리뷰를 꼼꼼히 본 후에 코드를 보면 이해하기 한결 수월한 것 같다. Keep going..
reference
Paper : arxiv.org/abs/1804.02767
Review : www.youtube.com/watch?v=HMgcvgRrDcA
Github code(pytorch) : github.com/eriklindernoren/PyTorch-YOLOv3
My code : github.com/tjems6498/YOLOv3
'Deep Learning' 카테고리의 다른 글
| [논문리뷰] EfficientNet (0) | 2021.02.21 |
|---|---|
| [논문리뷰] Mobilenet v2 (0) | 2021.02.14 |
| [논문리뷰] YOLO v1 (0) | 2021.01.31 |
| Linear Regression (1) | 2021.01.26 |
| [논문리뷰] SSD : Single Shot Multibox Detector (2) | 2021.01.23 |
